M3KE评估数据集分享
M3KE评估数据集分享
M3KE数据集是一种针对大语言模型的多层次、多主题的知识评估数据集,旨在衡量中文大型语言模型在零样本和少样本设置中获取知识的能力。
1 数据集数据
M3KE 收集了 20,477 个真人标准化考试题目(包含 4 个候选答案),覆盖 71 个任务,包括小学、初中、高中、大学、研究生入学考试题目,涉及人文、历史、政治、法律、教育、心理学、科学、工程技术、艺术等学科。
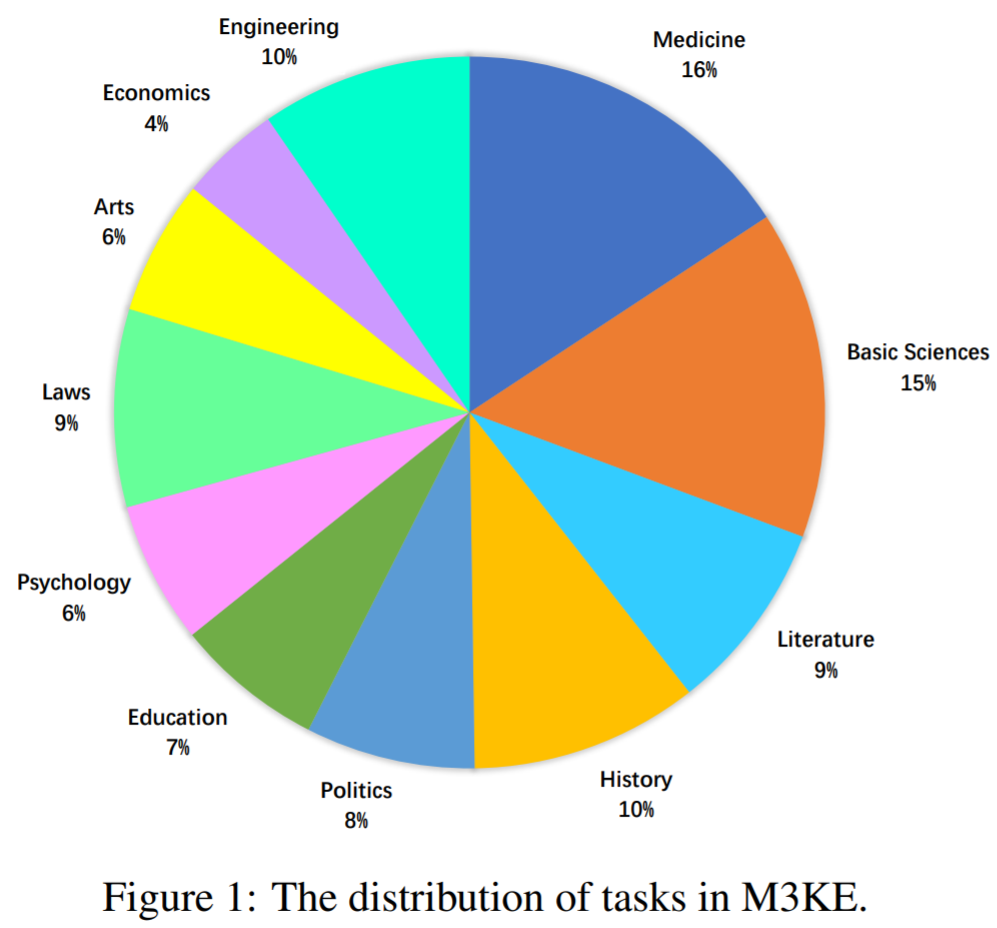
2 数据集优势
(1) 契合中国教育体系,覆盖多教育阶段
研究人员模仿中国学生的教育经历,即小学、初中、高中、大学等主要教育阶段,旨在评估中文大模型在不同教育阶段下的表现。由于每个教育阶段需要掌握的知识点不同(例如,在语文学科中,小学和初中的知识或考点存在明显的差异),因此,M3KE 在不同教育阶段会包含相同的学科。为了提高数据集中学科知识点的覆盖范围,研究人员选择了中国升学考试中的统考试题,包括小升初、中考、高考,研究生入学考试和中国公务员考试等真题题目。
(2) 覆盖多学科领域
为提高数据集的学科覆盖率,研究人员基于人文艺术、社会科学和自然科学三大类进行构建,包括:文学、理学,历史、政治、法学、教育学、心理学、科学、工程技术、艺术等学科。为进一步拓展数据集的丰富度,研究人员补充了中医、宗教以及计算机等级考试等任务。
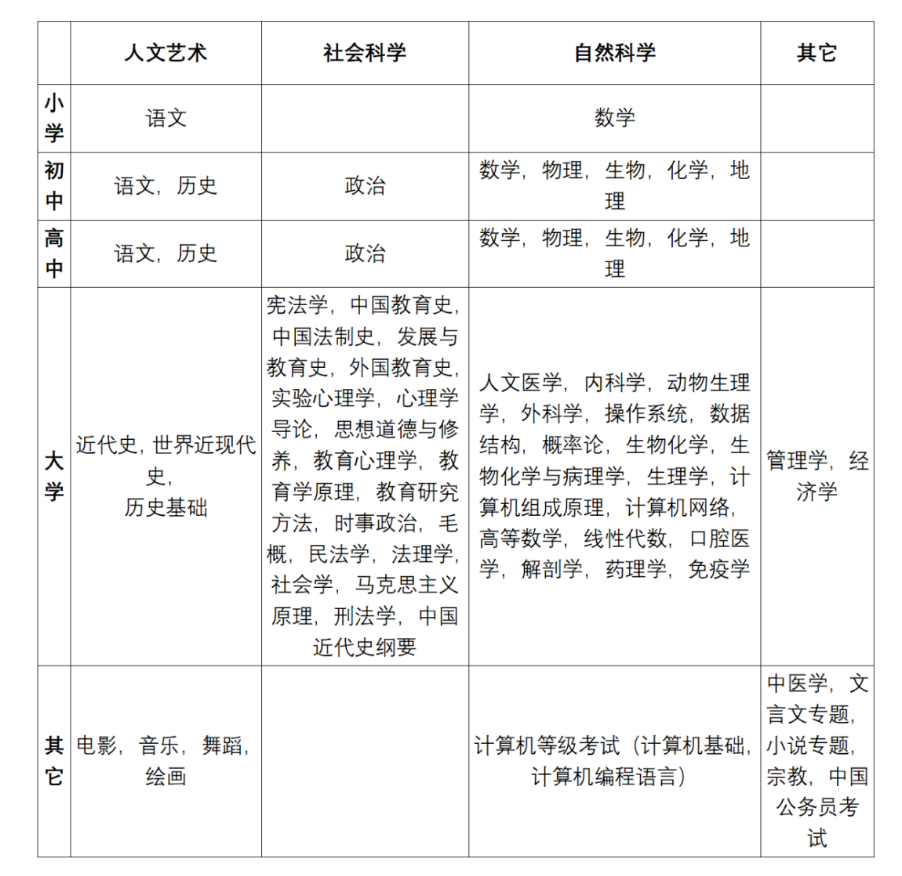
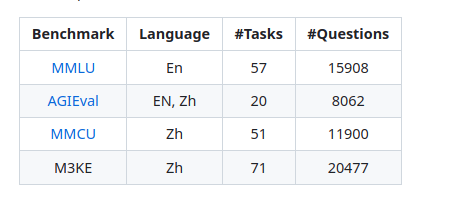
3 评估结果
在零样本设置条件下,模型要求直接回答问题;在少样本设置条件下,会预先给定模型同任务的若干示例,引导模型进行情景学习(In-Context Learning)。在 M3KE 中,所有题目均使用准确率计算得分。
(1) 不同学科类别下的模型零样本/少样本评估结果
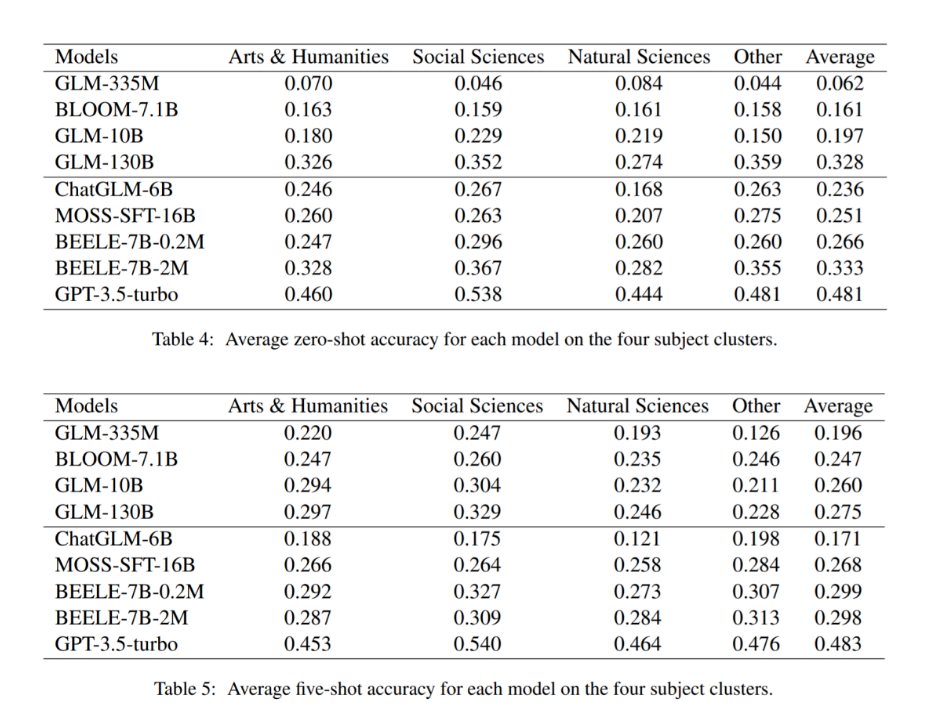
(2) 不同教育阶段下的模型零样本/少样本评估结果
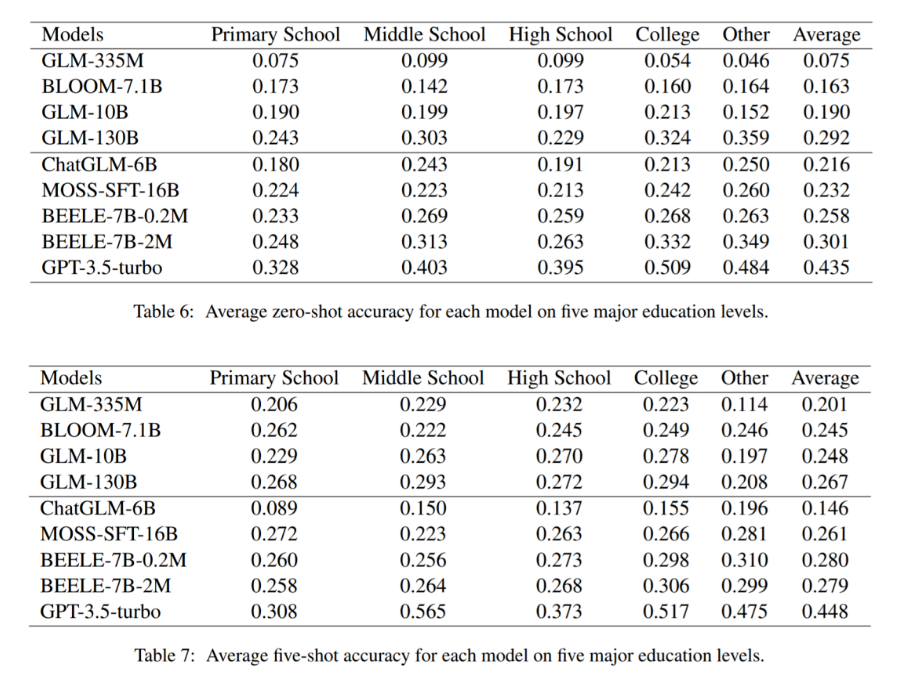
4 评估结果分析
(1)在零样本评估中(Table 4&6),所有参数小于 10B 的预训练语言模型(未经过微调)准确率都低于随机结果(25%),少样本的设置(Table 5&7)有助于模型性能的提升。但是,GLM130B 在零样本评估的结果好于少样本评估结果,原因可能是 GLM130B 在预训练阶段已经使用了部分指令数据,使其已经具备较好的零样本学习能力。
(2)大部分经过微调后的中文大模型仅达到随机结果(25%)水平,即使在小学阶段的测试中(Table 6&7)。这说明较低教育阶段中的知识仍然是当前中文大模型的短板之一。
(3)在零样本评估中,BELLE-7B-2M 取得了中文大模型中最好的成绩,但仍然与 GPT-3.5-turbo 有 14.8% 的差距。此外,有监督微调指令的数量也是一个重要的因素,经过两百万指令微调的 BELLE-7B-2M 好于经过二十万指令微调的 BELLE-7B-0.2M(Table 4)。