是重复还是不重复:在令牌危机下扩展LLM的见解
是重复还是不重复:在令牌危机下扩展LLM的见解
新加坡国立大学的研究人员发布了一篇全新的论文《To Repeat or Not To Repeat: Insights from Scaling LLM under Token-Crisis》,研究了大语言模型的Epoch次数设置问题。文章讨论了在重复的数据集上进行多次训练对大语言模型性能的影响。作者指出,随着大语言模型的规模和训练数据集中Token数量的增加,模型性能受到很大的影响。然而,现有的数据集中的Token数量有限,模型参数规模的增长可能会导致Token不足的情况,被称为"Token危机"。
1 问题提出
作者提出了一系列问题:
预训练数据集重复的影响是什么?
影响多次轮次(Epoch)训练效果下降的原因是什么?
正则化可以降低多Epoch的影响吗
通过混合专家模型(Mixture of Experts,MoE)扫描确定稠密模型的最佳超参数
作者采用T5模型和C4数据集进行实验,得出结论。
2 背景
在此前的研究中,大家发现大语言模型的规模和训练数据集中词元(Token)的数量对模型的性能有很大的影响。大模型扩展定律都认为模型的规模与训练数据的规模必须同时扩大才能让模型产生更好的性能。但是,Token数量似乎并不是很足够,如下图所示是作者研究的模型参数规模增长和目前互联网是可用的数据集Token数量增长情况。
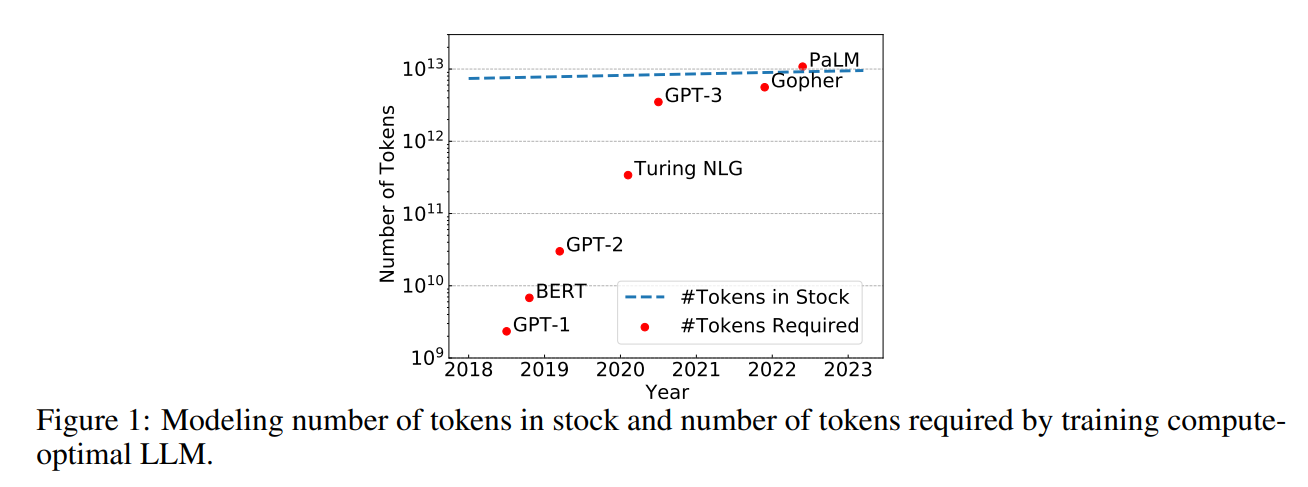
例如,Meta AI训练的LLaMA-65B模型用了1.4万亿Token,而2023年全球的Token估计只有9万亿!按照目前模型规模的发展情况,在2023年-2027年几年的时间里,我们的模型将把全球所有数据集的Token都训练完成,此后,我们很可能陷入缺少Token训练的地步,这被作者称为Token危机。
大语言模型的训练Epoch通常都是1-2次,多的也都是个位数。2022年,Hoffmann的论文中提出用重复的Token训练大语言模型会让模型降低性能,而Taylor在训练Galactica模型时候发现Epoch次数达到4次也可以提升模型效果。显然,在重复数据集上训练多次对模型的影响目前还没有一个相对完善的研究。但是这个问题很重要!
3 实验结论
3.1 模型参数规模与Token数量需要匹配
首先是模型参数规模的增长与模型需要的Token数量基本是呈线性的。
作者比较了在各种计算预算下掩码标记预测的验证准确性。当较大的模型优于较小的模型时,表明较小的模型已收到足够的Token。用于训练较小模型的Token数量可以被视为完整训练的Token要求。
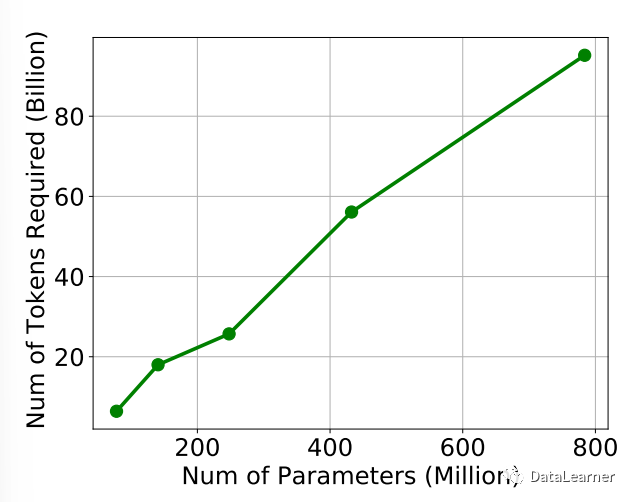
这意味如果你要充分训练一个大型语言模型(Large Language Model,LLM),需要根据它的参数数量来收集足够的Token。
3.2 多轮Epoch的训练会降低模型性能
作者分别使用C4数据集的子集,然后只是用了其中一部分数据集,并通过设置多次Epoch来让模型总的训练过的Token差不多水平,观察模型的性能。
如图3.2所示,可以看到,数据集重复的次数越多,模型的性能越差:
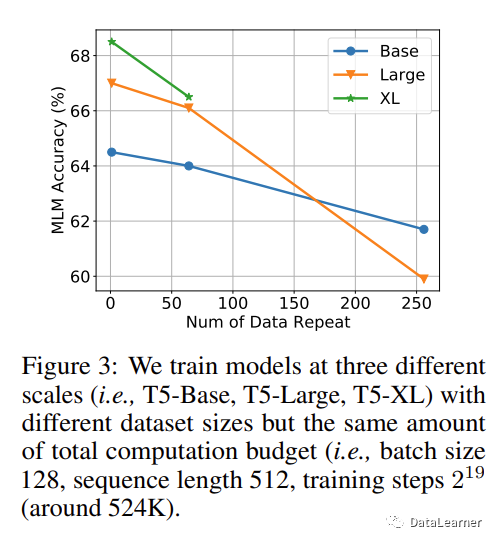
此外,如果Token数量不够,模型参数规模越大,越容易出现过拟合的现象。
尽管重复数据上的训练会降低预训练模型的效果,但是这种方式对于下游任务的影响也没有人探测过。因此,作者也继续做了这方面的研究,得到的结论是在下游任务上也会出现,即如果预训练模型在重复数据上进行,尽管训练的总的Token数量可能一致,但是,其下游任务的效果也是更差!
因此,我们的下一个调查围绕着使用重复数据训练 LLM。 为了探索这一点,我们随机选择了 C4 数据集的几个子集,其中包含大约 235,229 和 227 个标记,导致每个标记分别重复 1、26 和 28 次。结果如图 3 所示,展示了预期的性能 使用重复标记训练 LLM 时的退化。 此外,我们观察到较大的模型在Token危机条件下更容易过度拟合。具体而言,在没有足够大的数据集的情况下进行训练时,T5-XL 尽管消耗更多的计算资源,但在访问 4x 数据时比 T5-Large 表现更差( 229 对 227 个Token)
3.3 更大规模的数据集会缓解重复Epoch对模型性能下降的影响
在这个实验中,作者将重复的次数固定,然后看模型在不同规模数据集上重复训练的性能影响。如图3.3所示。
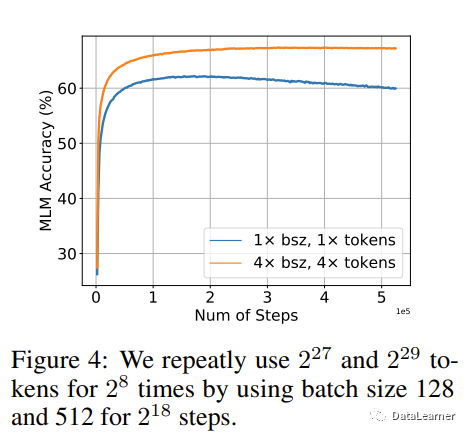
可以看到,当在227个Token和229个Token上重复训练28次之后发现,前者更容易出现过拟合,而229Token的数据集上重复训练,模型性能下降不明显。
3.4 提高数据集的质量也无法挽救重复训练带来的过拟合
Taylor在训练银河战舰(Galactica)模型时候认为他之所以用4 Epoch能提高训练效果可能是因为他的数据集质量更好。然而,本文的作者发现,相对更高质量的数据集并不能降低重复训练带来的影响。
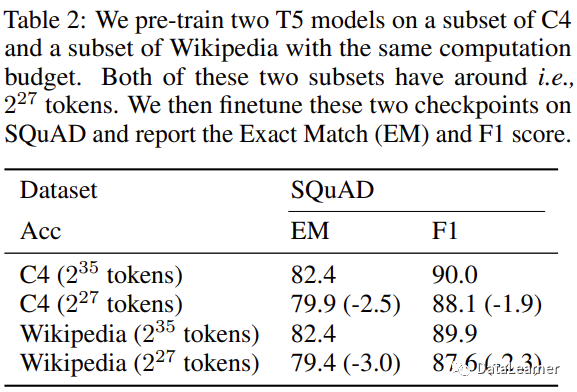
作者用相同的重复策略在C4数据集和维基(Wikipedia)数据集上分别训练模型,发现二者都会因为重复训练带来模型性能的下降。这里的Wikipedia数据集质量相对C4更好一点。说明相对提高数据集质量可能不会影响重复训练的负面效应。
3.5参数数量和FLOPs在重复训练上的影响
模型规模的增长其实表现在2个方面,一个是模型参数,一个是模型所需要的计算量。模型参数相同的情况下,采用不同的模型架构所需要的浮点运算次数(Floating Point Operations,FLOPs)是不同的。作者对比了MoE架构,并采用参数共享(ParamShare)方法降低相同参数模型的FLOPs。
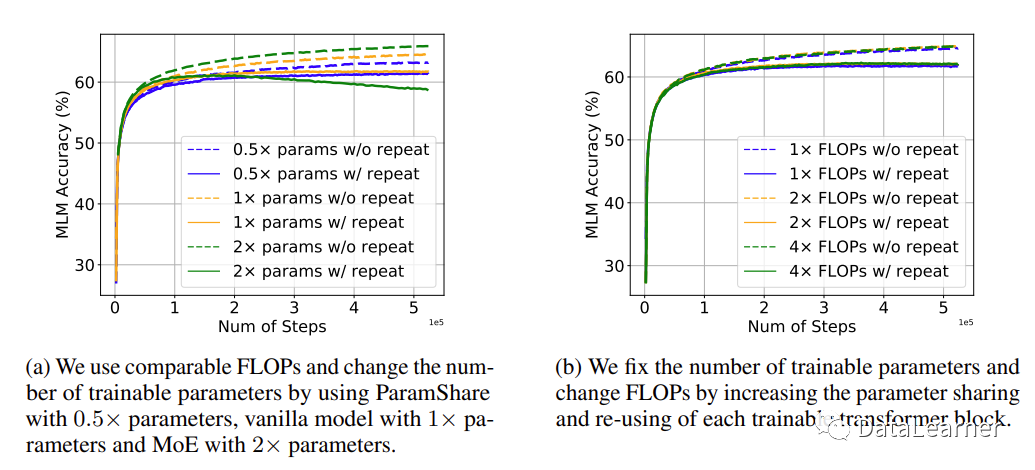
经过测试发现,FLOPs较大的模型性能会更好一点,但是依然无法有效降低重复训练带来的模型损失。
3.6 小计算量模型的过拟合趋势与大计算量的差不多
这是一个有趣的发现,尽管在前面的实验中,相同参数规模不同计算量的模型都会受到重复数据集训练的影响。但是二者在模型性能表现的趋势上类似。
这意味着我们可以利用较低计算量的模型预估大模型的训练结果。在大语言模型的训练中,训练成本很高。采用类似的模型,但是更低的计算量来预估模型的表现将十分有价值!
3.7 多样的训练目标可以减轻多Epoch下降吗?
目前大语言模型的训练目标有很多,例如预测下一个单词是神什么的生成式目标,也有把单词masked之后用来判断是什么单词的判别式目标。如果语言模型的训练目标多样化,那么实际上更加可能受到多Epoch带来的性能损失。
例如,UL2这种模型就不适合多Epoch的训练,MLM这种模型受到的影响反而更小。
3.8 Dropout是一个被大语言模型忽视的正则技术,虽然慢,但是可以降低多Epoch的影响
正则技术,如随机丢弃(Dropout)、路径随机失活(Droppath)、权重衰减(Weight Decay,WD)等都是常用的防止过拟合的技术。而多Epoch的负面影响也都是过拟合。因此,作者研究了这些正则技术是否可以降低多Epoch的影响。
在目前超过100亿参数规模的大语言模型中,如GPT-3、PaLM、LLaMA等,都没有使用Dropout(可能是因为太慢了)。而前面说的Galactica训练使用了,这是Galactica能够训练4 Epoch提升性能的最重要的原因。
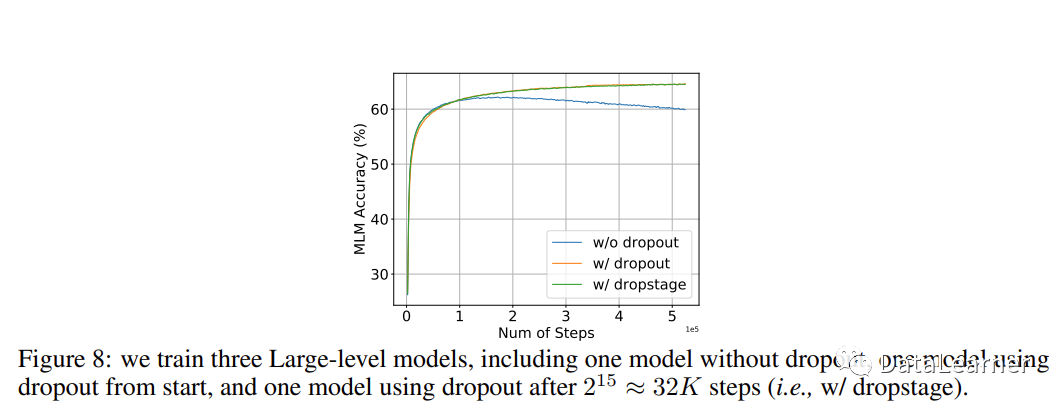
3.9 在训练过程中逐渐使用Dropout是有效的策略
在前面的讨论中,作者已经发现Dropout可以降低多Epoch的影响,但是Dropout会降低模型的性能。因此,作者考虑不在全部训练中使用Dropout,而是逐渐引入。
最终发现,如果前期训练不用Dropout,在后续的迭代中使用Dropout也是有效的!
3.10 Dropout对不同规模模型的影响不同
尽管前面已经证明Dropout使用可以降低多Epoch的影响,但是在不同规模模型下是不同的。对于规模较大的模型,Dropout不能有效降低多Epoch带来的坏处!
3.11 通过MoE扫描确定稠密模型的最佳超参数
最后一个结论其实与Epoch关系不大,作者强调的是MoE的模型表现与大模型真正的训练有类似的趋势,因此用MoE去提前预估大模型的性能,做参数调优是一个非常好的思路。
4 总结
根据前面的实验我们知道,如果在Token数量一定的数据集上做多Epoch的模型训练,会影响模型的性能,降低模型的效果。这在预训练和下游任务都会产生影响。但是,随着模型的发展,高质量数据集的Token数将很快用完。而采用正则技术虽然会影响模型训练效率,但是会降低这种影响。
所有的一切表明,在不久的将来,我们会面临Token训练完的危机,这时候多Epoch显然不是好的方向,这意味着我们应该寻找新的大语言模型的方向,或者说可能很快我们也会达到现有LLM的天花板。