PEFT:最先进的参数高效微调方法
PEFT:最先进的参数高效微调方法
参数高效微调 (PEFT) 方法能够将预训练的语言模型 (PLM) 有效地适应各种下游应用程序,而无需微调模型的所有参数。微调大型 PLM 的成本通常高得令人望而却步。在这方面,PEFT方法仅微调少量(额外)模型参数,从而大大降低了计算和存储成本。
代码地址:https://github.com/huggingface/peft
1 PEFT定义
PEFT,即参数高效微调 (Parameter-Efficient Fine-Tuning)技术,同时是Hugging Face开源的一个高效微调大模型的库。
PEFT能够将预训练的语言模型 (PLM) 有效地适应各种下游应用程序,而无需微调模型的所有参数。在微调大型 PLM时,PEFT方法仅微调少量(额外)模型参数,从而大大降低了计算和存储成本。最近的PEFT技术实现了与完全微调相当的性能。
2 PEFT分类
Hugging Face开源的PEFT库目前支持5种方法,分别是:
(1)LoRA: LoRA: Low-Rank Adaptation of Large Language Models(微软,2021年10月)
(2)AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning(微软,2023年3月)
(3)Prefix Tuning: Prefix-Tuning: Optimizing Continuous Prompts for Generation(斯坦福,2021年8月);P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks(清华KEG,2022年3月20);Prefix Tuning在input前面加入prefix部分,并针对拥有自由参数的prefix部分进行微调训练
(4)P-Tuning: GPT Understands, Too(清华,北京智源,2021年3月18);P-Tuning将prompt对应的token替换为可训练的嵌入,并进行微调训练
(5)Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning(谷歌,2021年9月);Prompt Tuning针对每一类任务,训练出任务对应prompt的embedding向量
其中,Prefix Tuning、P-Tuning、Prompt Tuning可理解为针对prompt部分的微调。
2.1 LoRA
LoRA,英文全称Low-Rank Adaptation of Large Language Models,直译为大语言模型的低阶适应,是微软的研究人员为了解决大语言模型微调而开发的一项技术。
LoRA的做法是,冻结预训练好的模型权重参数,然后在每个Transformer块里注入可训练的层,由于不需要对模型的权重参数重新计算梯度,所以,大大减少了需要训练的计算量。
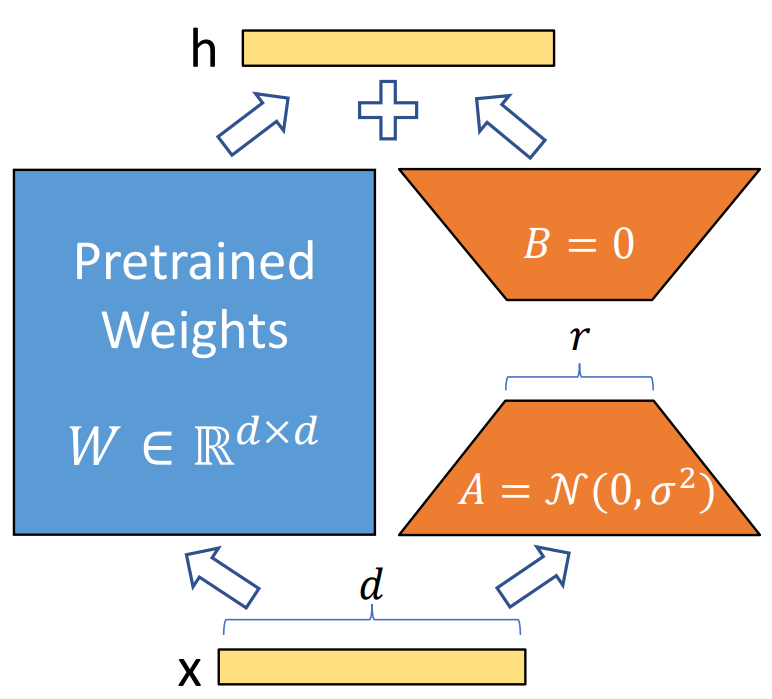
结合上图,可以直观地理解LoRA的实现原理。LoRA冻结预训练模型权重,并将可训练的秩分解矩阵注入到Transformer层的每个权重中,大大减少了下游任务的可训练参数数量。直白的来说,实际上是增加了右侧的“旁支”,也就是先用一个Linear层A,将数据从 d维降到r,再用第二个Linear层B,将数据从r变回d维。最后再将左右两部分的结果相加融合,得到输出的hidden_state。
对于左右两个部分,右侧看起来像是左侧原有矩阵W的分解,从而将参数量从 n ∗ n 变成了n * r + n * r ,在 r < < n 的情况下,参数量就大大地降低了。
事实上,该思想与Albert的思想有异曲同工之处,在Albert中,作者通过两个策略降低了训练的参数量,其一是Embedding矩阵分解,其二是跨层参数共享。
在Albert中,作者考虑到词表的维度很大,所以将Embedding矩阵分解成两个相对较小的矩阵,用来模拟Embedding矩阵的效果,这样一来需要训练的参数量就减少了很多。
LORA也是类似的思想,并且它不再局限于Embedding层,而是所有出现大矩阵的地方,理论上都可以用到这样的分解。
但是与Albert不同的是,Albert直接用两个小矩阵替换了原来的大矩阵,而LORA保留了原来的矩阵W,但是不让W参与训练,所以需要计算梯度的部分就只剩下旁支的A和B两个小矩阵。
从论文中的公式来看,在加入LORA之前,模型训练的优化表示为:
其中,模型的参数用 Φ 表示。
而加入了LORA之后,模型的优化表示为:
其中,模型原有的参数是Φ ,LORA新增的参数是Δ Φ ( Θ )。
从第二个式子可以看到,尽管参数看起来增加了(多了Δ Φ ( Θ ) ),但是从前面的max的目标来看,需要优化的参数只有Θ ,而根据假设,Θ < < Φ,这就使得训练过程中,梯度计算量少了很多,所以就在低资源的情况下,我们可以只消耗Θ这部分的资源,这样一来就可以在单卡低显存的情况下训练大模型了。
但是相应地,引入LoRA部分的参数,并不会在推理阶段加速,因为在前向计算的时候,Φ部分还是需要参与计算的,而Θ部分是凭空增加了的参数,所以理论上,推理阶段应该比原来的计算量增大一点。
根据论文的研究结果分析,LoRA的微调质量与全模型微调相当。
2.2 AdaLoRA
AdaLoRA,即自适应预算分配以实现参数有效的微调,是微软与佐治亚理工学院共同提出的一种微调优化方法。
由于在不太重要的权重矩阵添加更多的参数会产生很少的收益,甚至会损害模型性能,因此论文提出了以下问题:
如何根据模块的重要性自适应地分配参数预算,以提高参数高效微调的性能?
为了回答这个问题,论文提出了一种新的方法——AdaLoRA(自适应的低秩自适应),该方法在类似LoRA的微调过程中在权重矩阵之间动态分配参数预算。具体而言,AdaLoRA调整增量矩阵的秩,以控制其预算。
关键的增量矩阵被分配了高秩,这样它们可以捕获更细粒度和特定于任务的信息。
不太重要的增量矩阵被修剪为具有较低的秩,以防止过度拟合并节省计算预算。
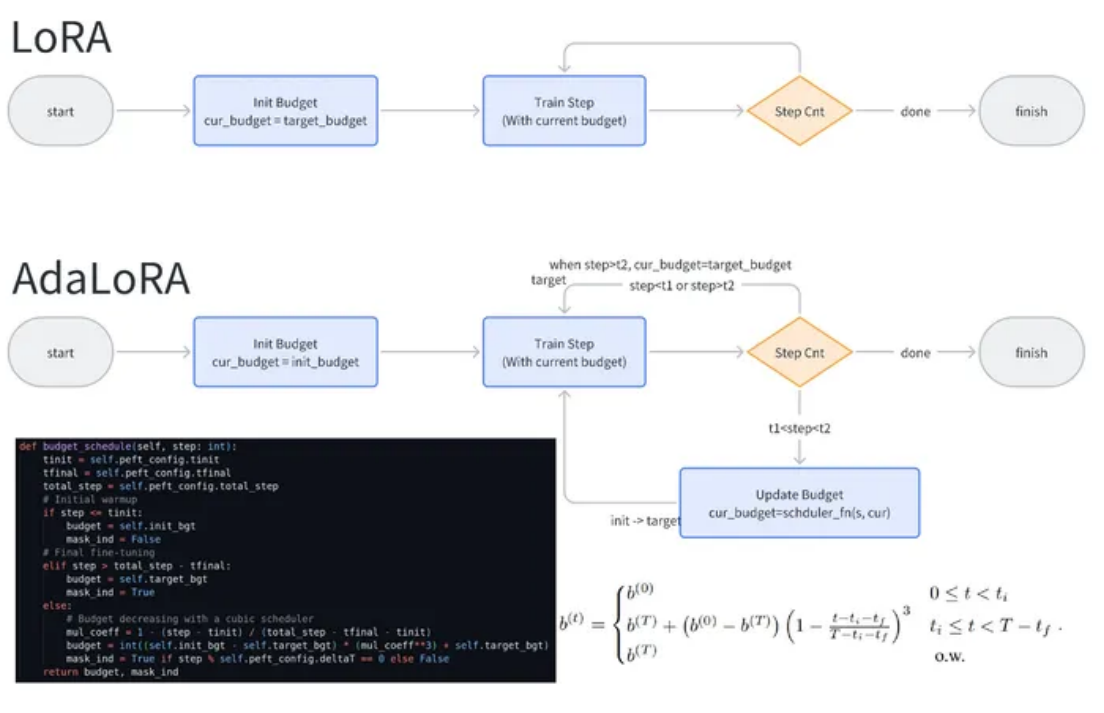
AdaLoRA包含两个重要组成部分:
(1)基于SVD的自适应,它以奇异值分解的形式表示增量矩阵∆;
(2)重要性感知秩分配,它根据我们新设计的重要性度量修剪冗余奇异值。
提示
奇异值:特征值的平方根
论文提出了两种重要性度量的方式,分别是:
(1)基于奇异值的重要性度量
(2)基于敏感性的重要性度量
在AdaLoRA中,以奇异值分解的形式对权重矩阵的增量更新进行参数化。然后,根据新的重要性指标,通过操纵奇异值,在增量矩阵之间动态地分配参数预算。这种方法可以有效地提高模型性能和参数效率。
AdaLoRA根据重要性评分自适应地分配参数预算,通过对权重矩阵进行重要性评分,有效地分配参数预算。
在现有的矩阵近似文献中,有一些控制矩阵秩的方法(Cai等人,2010;Koltchinskii等人,2011;Toh & Yun,2010)。它们大多直接计算矩阵的奇异值分解(SVD),然后截断最小的奇异值。这样的操作可以显式地操纵秩,更重要的是,最小化结果矩阵和原始矩阵之间的差异。
然而,对于微调大型模型,迭代地将SVD应用于大量高维权重矩阵会变得非常昂贵。因此,论文没有精确计算SVD,而是将∆参数化为∆=P∧Q,以模拟SVD。对角矩阵∧包含奇异值,而正交矩阵P和Q表示∆的左/右奇异向量。为了正则化P和Q的正交性,在训练损失中增加了额外的惩罚。这样的参数化避免了SVD的密集计算。此外,另一个优点是,该方法只需要在保持奇异向量的同时删除不重要的奇异值。这保留了未来恢复的可能性,并稳定了训练。
基于SVD参数化,AdaLoRA通过重要性评分动态调整∆=P V Q的等级。
具体来说,AdaLoRA将增量矩阵P∧Q划分为三元组,其中每个三元组Gi包含第i个奇异值和相应的奇异向量。为了量化三元组的重要性,AdaLoRA提出了一种新的重要性度量,它考虑了Gi中每个条目对模型性能的贡献。
具有低重要性分数的三元组被授予低优先级,因此奇异值被清零。
具有高度重要性的三元组会被保留,并进行微调。
2.3 prompt分类
prompt分为hard prompt与soft prompt两种,这两种prompt的含义如下。
(1)hard prompt 又称为 Discrete Prompt,离散prompt是一个实际的文本字符串
(2)soft prompt 又称为 Continuous Prompts,连续prompt直接在底层语言模型的嵌入空间中进行描述
prompt的制作分为手工创建prompt和自动化生成prompt,而自动化生成prompt又分为离散提示(又叫做硬提示)和连续提示(又叫做软提示)
2.4 Prefix Tuning
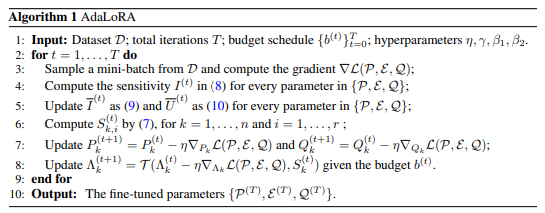
前缀微调(Prefix-Tuning),是用于 生成任务(NLG) 的轻量微调。
Prefix-Tuning与Full-finetuning更新所有参数的方式不同,该方法是在输入token之前构造一段任务相关的virtual tokens作为Prefix,然后训练的时候只更新Prefix部分的参数,而Transformer中的其他部分参数固定。
该方法其实和构造Prompt类似,只是利用多层感知编码prefix,注意多层感知机就是prefix的编码器,不再像Prompt是人为构造的“显式”的提示,并且无法更新参数,而Prefix则是可以学习的“隐式”的提示。
对于Decoder-Only的GPT,prefix只加在句首,[PREFIX, x, y],对于Encoder-Decoder的BART,不同的prefix同时加在编码器和解码器的开头,[PREFIX, x, PREFIX', y]。在下游微调时,LM的参数被冻结,只有prefix部分的参数进行更新。不过这里的prefix参数不只包括embedding层而是虚拟token位置对应的每一层的activation都进行更新。
Prefix-Tuning将一系列连续的task-specific向量添加到input前面,称之为前缀,如下图中的红色块所示。
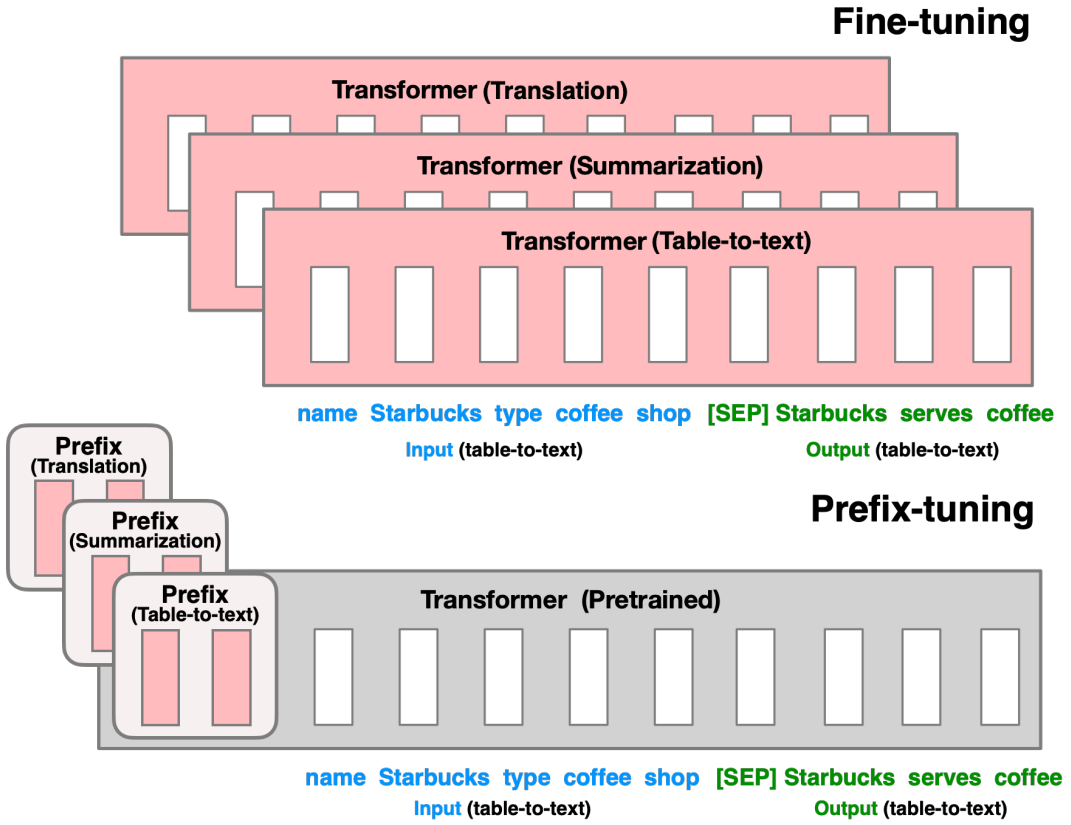
Prefix-Tuning的作者提出了Prefix Tuning,该方法冻结LM参数,并且只优化Prefix(红色前缀块)。因此,只需要为每个任务存储前缀,使前缀调优模块化并节省空间。
与提示(prompt )不同的是,前缀完全由自由参数组成,与真正的token不对应。相比于传统的微调,前缀微调只优化了前缀。因此,我们只需要存储一个大型Transformer和已知任务特定前缀的副本,对每个额外任务产生非常小的开销。
原论文仅在以下任务中进行了比较:
(1)table-to-text生成任务:GPT-2
(2)生成式摘要任务:BART
Prefix-tuning的prompt拼接方式
Prefix-tuning是做生成任务,它根据不同的模型结构定义了不同的Prompt拼接方式,在GPT类的自回归模型上采用[PREFIX, x, y],在T5类的encoder-decoder模型上采用[PREFIX, x, PREFIX', y]:
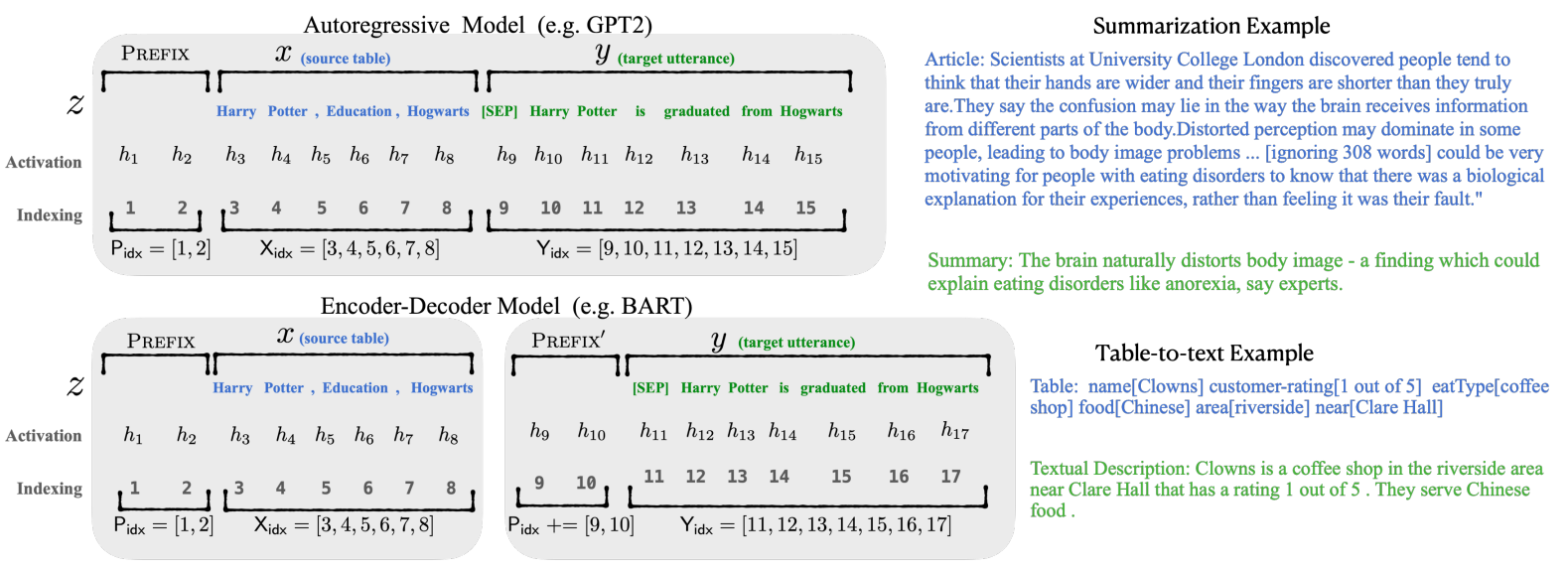
值得注意的还有三个改动:
(1)把预训练大模型freeze住,因为大模型参数量大,精调起来效率低,毕竟prompt的出现就是要解决大模型少样本的适配;
(2)作者发现直接优化Prompt参数不太稳定,加了个更大的MLP,训练完只保存MLP变换后的参数就行了;
(3)实验证实只加到embedding上的效果不太好,因此作者在每层都加了prompt的参数,改动较大。
2.5 Prompt Tuning
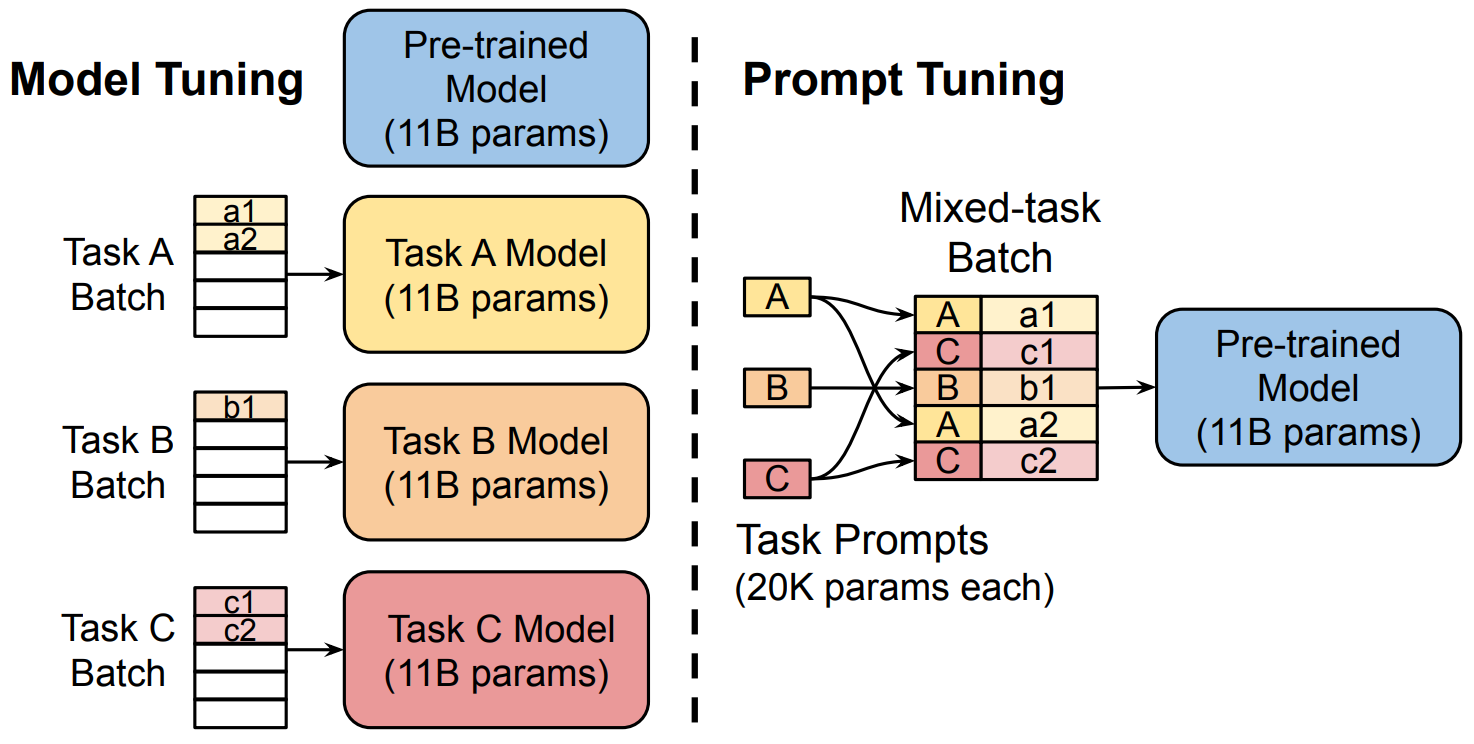
Prompt-tuning 固定预训练参数,为每一个任务(a1、a2、b1、b2)额外添加一个或多个 embedding(A、B、C)。
之后拼接 query 正常输入 LLM ,并只训练这些 embedding 。左图为单任务全参数微调,右图为 prompt tuning 。
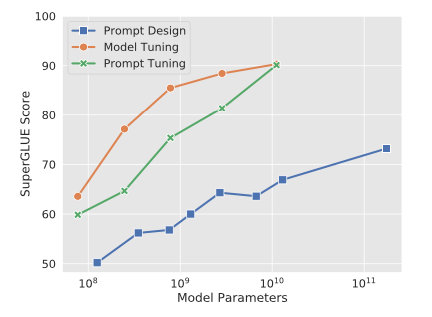
Prompt-tuning给每个任务定义了自己的Prompt,拼接到数据上作为输入,同时freeze预训练模型进行训练,在没有加额外层的情况下,可以看到随着模型体积增大效果越来越好,最终追上了精调的效果:
同时,Prompt-tuning还提出了Prompt-ensembling,也就是在一个batch里同时训练同一个任务的不同prompt,这样相当于训练了不同「模型」,比模型集成的成本小多了。
2.6 P-Tuning
Prompting最初由人工设计Prompt,自然语言提示本身十分脆弱(如下图所示,选择不同的Prompt对下游任务的性能影响较大),而且从优化角度无法达到最优。
为消除这一影响,P Tuning技术应用而生:P-Tuning v1将自然语言提示的token,替换为可训练的嵌入,同时利用LSTM进行Reparamerization加速训练,并引入少量自然语言提示的锚字符(Anchor,例如Britain)进一步提升效果,如图2.8所示。
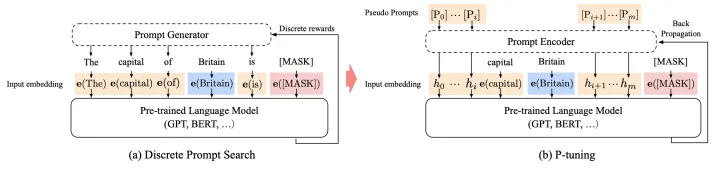
P-Tuning v1,对于BERT类双向语言模型采用模版(P1, x, P2, [MASK], P3),对于单向语言模型采用(P1, x, P2, [MASK])。
P-Tuning v2提升小模型上的Prompt Tuning,最关键的就是引入Prefix-tuning技术。
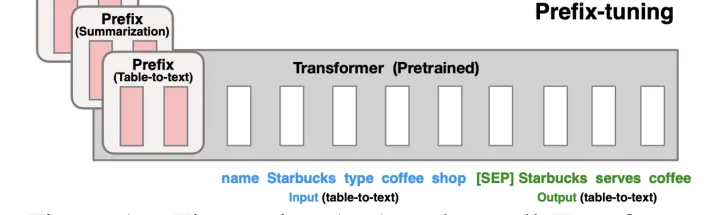
Prefix-tuning(前缀微调)最开始应用在NLG任务上,由[Prefix, x, y]三部分构成,如上图所示:Prefix为前缀,x为输入,y为输出。Prefix-tuning将预训练参数固定,Prefix参数进行微调:不仅只在embedding上进行微调,也在TransFormer上的embedding输入每一层进行微调。
P-Tuning v2将Prefix-tuning应用于在NLU任务,如下图所示:
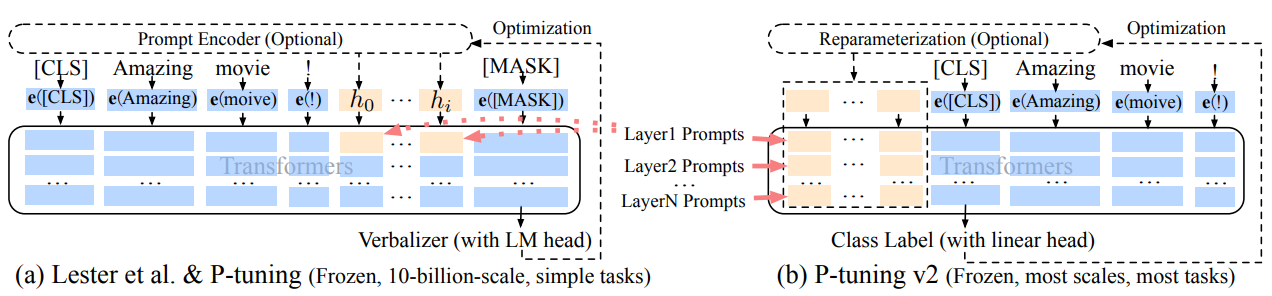
p tuning v2简单来说其实是soft prompt的一种改进。
soft prompt是只作用在embedding层中,实际测试下来只作用在embedding层的话交互能力会变弱,而且冻结模型所有参数去学习插入token,改变量偏小使得效果有时候不太稳定,会差于微调。
p tuning v2则不只是针对embedding层,而是将连续型token插入每一层,增大改变量和交互性。
soft prompt比较依靠模型参数量,在参数量超过10B的模型上,效果追上了fine-tune,但是p tuning v2因为每层插入了token,增大模型训练的改变量,更加适用于小一点的模型。
2.7 各类提示微调对比
模型:P-tuning (自动化地寻找连续空间中的知识模板)
特点:hard+soft
方法:传统离散prompt直接将模板T的每个token映射为对应的embedding,而P-Tuning将模板T中的Pi(Psedo Prompt)映射为一个可训练的参数 hi。使用BiLSTM对Pi序列进行表征,并加入锚字符(Anchor)提升效果。
模型:Prefix-Tuning
特点:生成任务,soft prompt
方法:在每层transformer 之前加入prefix,Prefix不是真实的 token,而是连续向量 (soft prompt)。
模型:Prompt tuning
特点:prefix-tuning的简化
方法:固定预训练模型,只对下游任务的输入添加额外的 k个 可学习的 token。
模型:P-tuning v2
特点:prefix-tuning的deep形式
方法:prefix-tuning仅在transformer的 第一层加入soft prompt,p tuning v2 提出 Deep Prompt Tuning的方法,在transformer 的每一层之前都加入了soft prompt。
3 实验结果
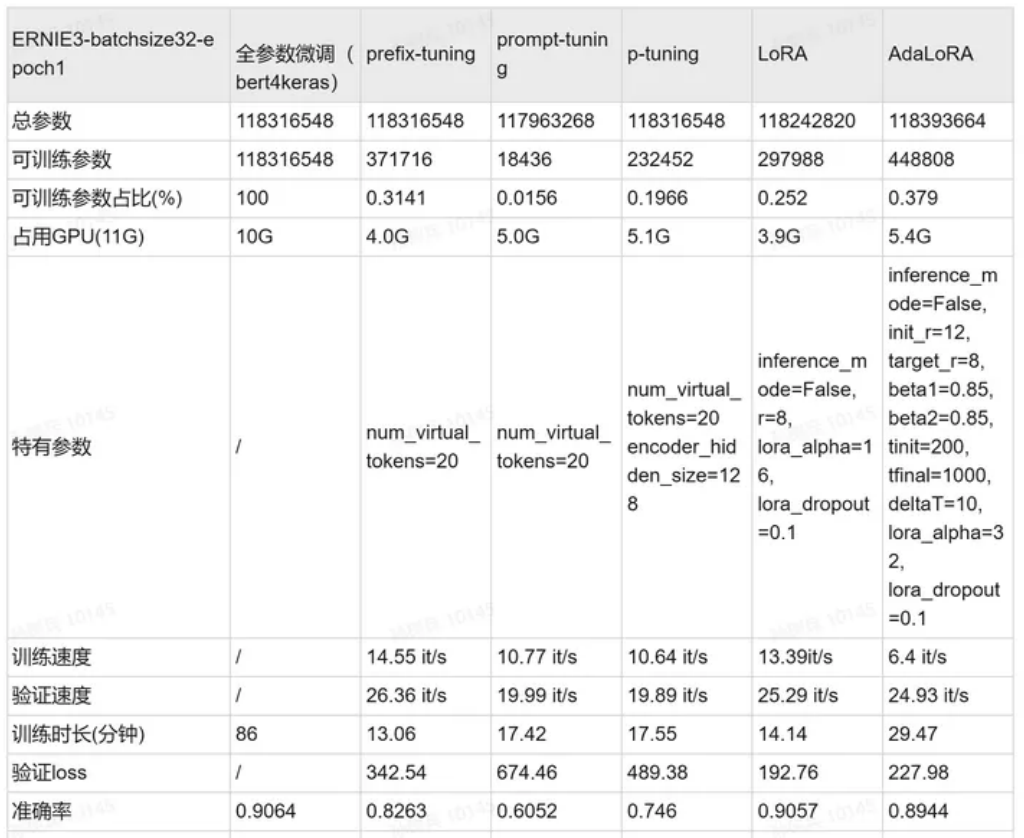
根据结果可以看出,在只训练1个epoch的情况下,只有LoRA与AdaLoRA的效果接近全参数微调,并且LoRA与全参数微调的差距不超过0.1%
4 参考文章
[1] 使用PEFT微调LLMs
[2] 《Prefix-Tuning: Optimizing Continuous Prompts for Generation》阅读笔记
[3] Prefix-Tunning
[4] 【prompt】什么是 Soft Prompt 和 Hard Prompt ?
[5] 【调研】Soft Prompt Tuning 模型发展调研:P-tuning,Prefix-tuning,Prompt-tuning,P-tuning v2
[6] prompt综述