S-LoRA:为数千个并发LoRA Adapter提供服务
S-LoRA:为数千个并发LoRA Adapter提供服务
S-LoRA 将所有Adapter存储在主存中,并将当前运行的查询使用的Adapter获取到 GPU 内存。为了有效利用GPU内存并减少碎片,S-LoRA提出了统一分页(Unified Paging)。
论文标题:S-LORA: SERVING THOUSANDS OF CONCURRENT LORA ADAPTERS
论文地址:https://arxiv.org/pdf/2311.03285.pdf
项目地址:https://github.com/S-LoRA/S-LoRA
1 介绍
S-LoRA 是专为众多 LoRA Adapter的可扩展服务而设计的系统,它将所有Adapter存储在主存中,并将当前运行查询所使用的Adapter取到 GPU 内存中。
S-LoRA 提出了「统一分页」(Unified Paging)技术,即使用统一的内存池来管理不同等级的动态Adapter权重和不同序列长度的 KV 缓存张量。此外,S-LoRA 还采用了新的张量并行策略和高度优化的定制 CUDA 内核,以实现 LoRA 计算的异构批处理。
这些功能使 S-LoRA 能够以较小的开销在单个 GPU 或多个 GPU 上为数千个 LoRA Adapter提供服务(同时为 2000 个Adapter提供服务),并将增加的 LoRA 计算开销降至最低。相比之下,vLLM-packed 需要维护多个权重副本,并且由于 GPU 内存限制,只能为少于 5 个Adapter提供服务。
与 HuggingFace PEFT 和 vLLM(仅支持 LoRA 服务)等最先进的库相比,S-LoRA 的吞吐量最多可提高 4 倍,服务的Adapter数量可增加几个数量级。因此,S-LoRA 能够为许多特定任务的微调模型提供可扩展的服务,并为大规模定制微调服务提供了潜力。
S-LoRA 包含三个主要创新部分。论文的第 4 节介绍了批处理策略,该策略分解了 base 模型和 LoRA Adapter之间的计算。此外,研究者还解决了需求调度的难题,包括Adapter集群和准入控制等方面。跨并发Adapter的批处理能力给内存管理带来了新的挑战。第 5 节,研究者将 PagedAttention 推广到 Unfied Paging,支持动态加载 LoRA Adapter。这种方法使用统一的内存池以分页方式存储 KV 缓存和Adapter权重,可以减少碎片并平衡 KV 缓存和Adapter权重的动态变化大小。最后,第 6 节介绍了新的张量并行策略,能够高效地解耦 base 模型和 LoRA Adapter。
2 批处理
对于单个Adapter,Hu et al., 2021 推荐的方法是将Adapter权重合并到 base 模型权重中,从而得到一个新模型(见公式 1)。这样做的好处是在推理过程中没有额外的Adapter开销,因为新模型的参数数与 base 模型相同。事实上,这也是最初 LoRA 工作的一个突出特点。
本文指出,将 LoRA Adapter合并到 base 模型中对于多 LoRA 高吞吐量服务设置来说效率很低。取而代之的是,研究者建议实时计算 LoRA 计算 xAB(如公式 2 所示)。
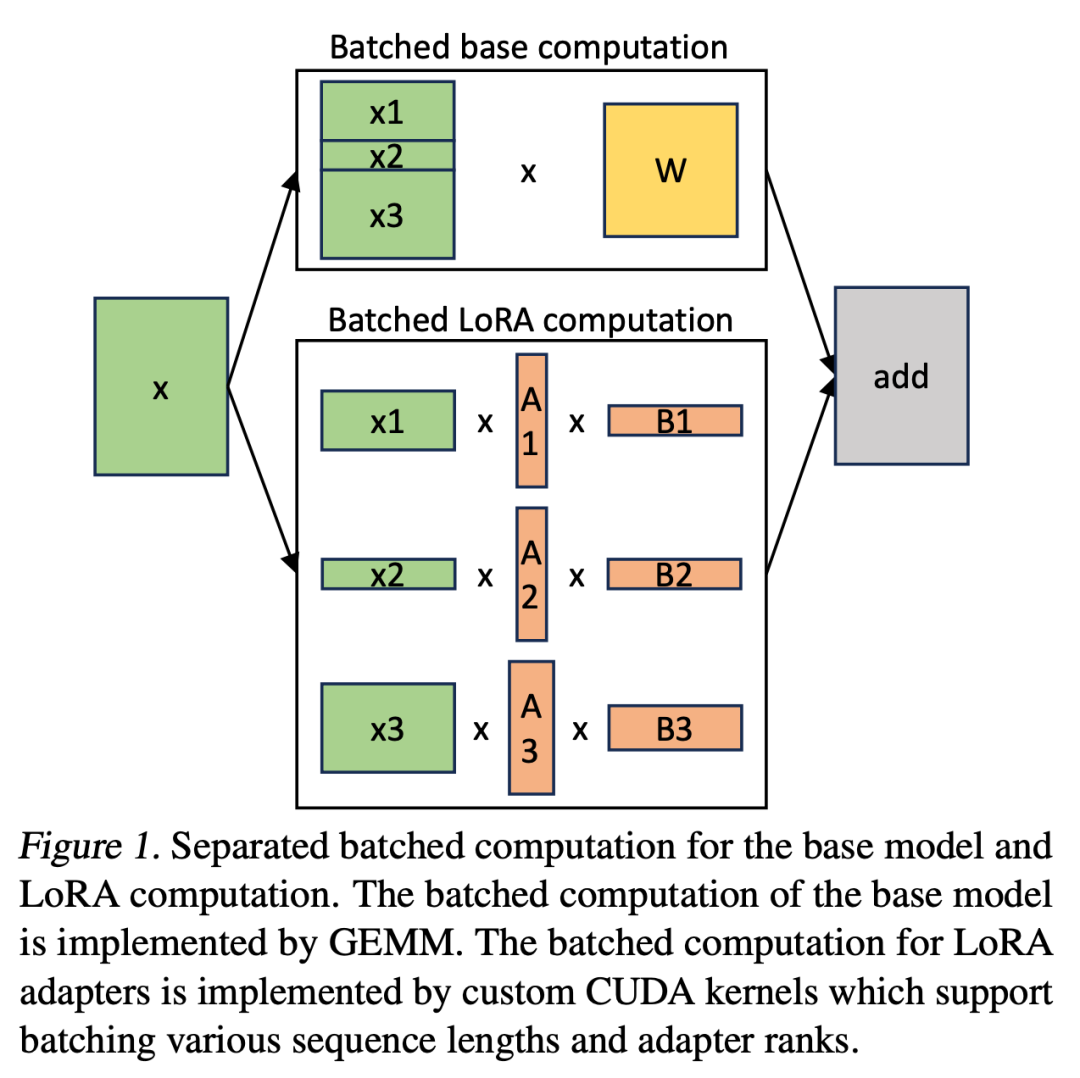
在 S-LoRA 中,计算 base 模型被批处理,然后使用定制的 CUDA 内核分别执行所有A大平台而的附加 xAB。这一过程如图 1.1 所示。研究者没有使用填充和 BLAS 库中的批处理 GEMM 内核来计算 LoRA,而是实施了定制的 CUDA 内核,以便在不使用填充的情况下实现更高效的计算。
3 Unified Paging
与为单个 base 模型提供服务相比,同时为多个 LoRA Adapter提供服务会带来新的内存管理挑战。为了支持多个Adapter,S-LoRA 将它们存储在主存中,并将当前运行批所需的Adapter权重动态加载到 GPU RAM 中。
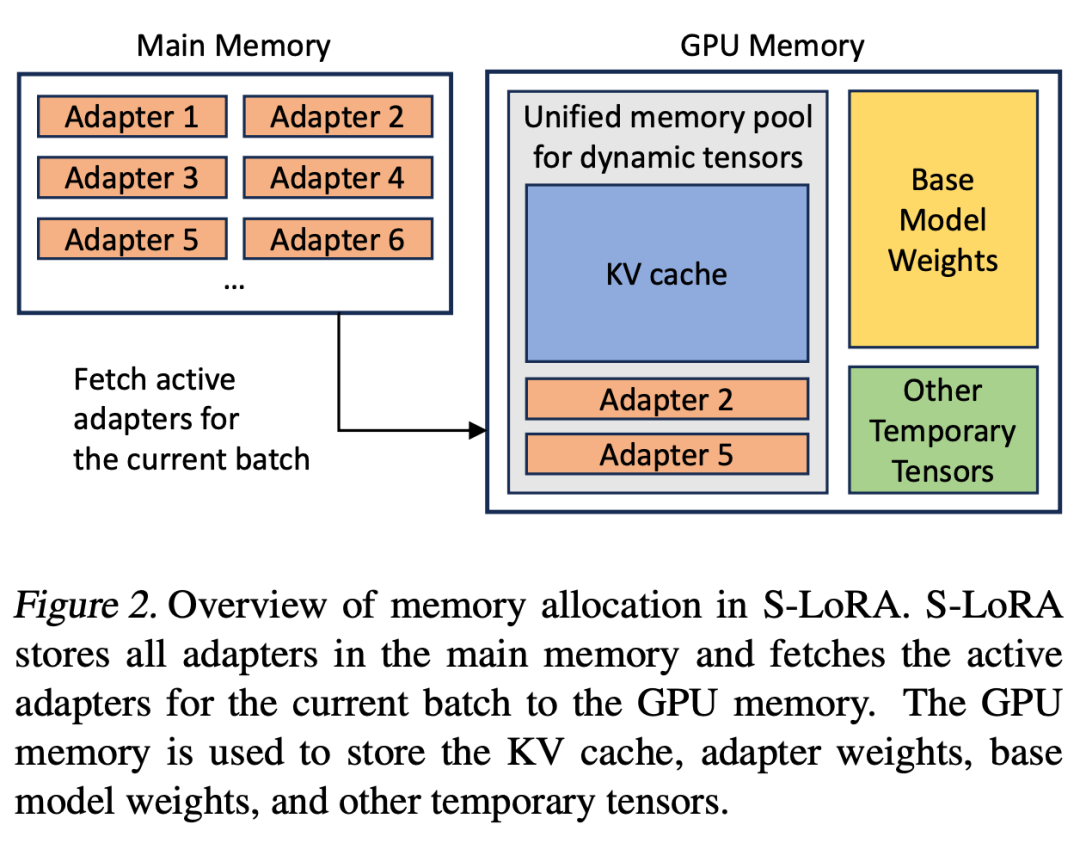
在这个过程中,有两个明显的挑战。首先是内存碎片,这是由于动态加载和卸载不同大小的Adapter权重造成的。其次是Adapter加载和卸载带来的延迟开销。为了有效解决这些难题,研究者提出了 「Unfied Paging」,并通过预取Adapter权重将 I/O 与计算重叠。
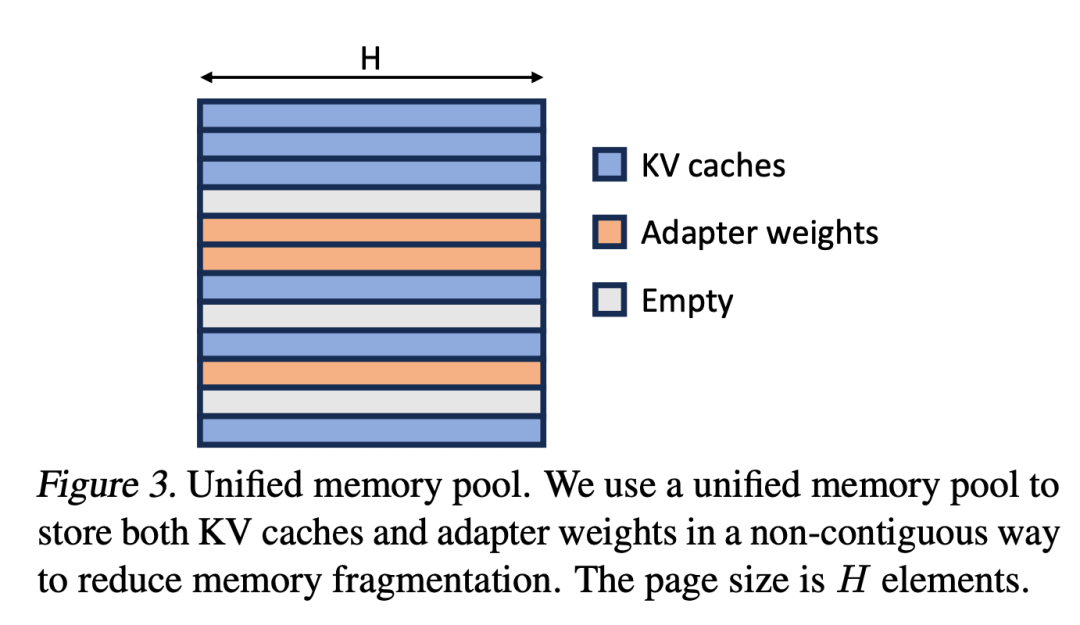
研究者将 PagedAttention 的想法扩展为统一分页(Unified Paging),后者除了管理 KV 缓存外,还管理Adapter权重。统一分页使用统一内存池来联合管理 KV 缓存和Adapter权重。为了实现这一点,他们首先为内存池静态分配一个大缓冲区,除了 base 模型权重和临时激活张量占用的空间外,该缓冲区使用所有可用空间。KV 缓存和Adapter权重都以分页方式存储在内存池中,每页对应一个 H 向量。因此,序列长度为 S 的 KV 缓存张量占用 S 页,而 R 级的 LoRA 权重张量占用 R 页。图 3 展示了内存池布局,其中 KV 缓存和Adapter权重以交错和非连续方式存储。这种方法大大减少了碎片,确保不同等级的Adapter权重能以结构化和系统化的方式与动态 KV 缓存共存。
4 张量并行
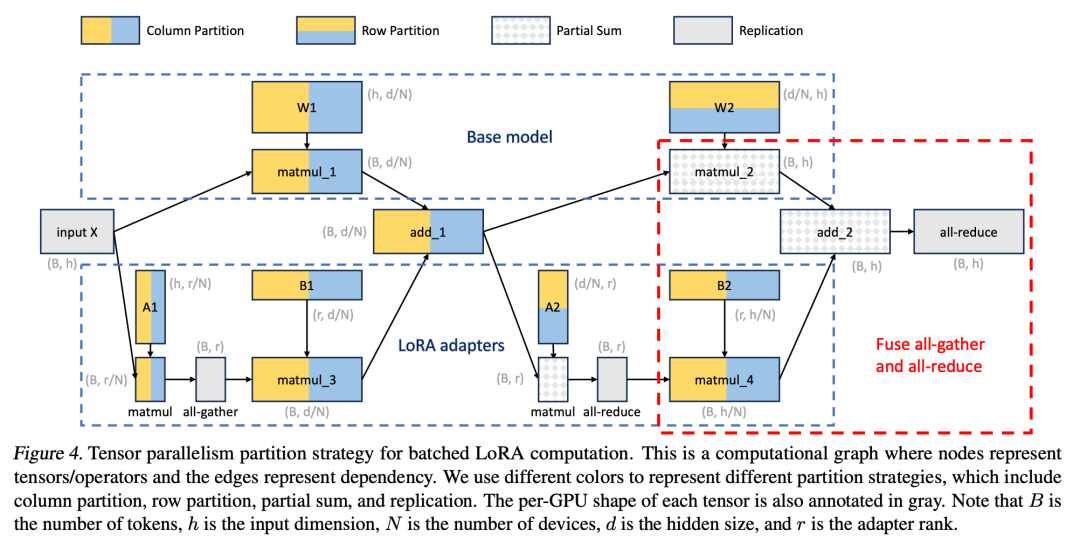
此外,研究者为批量 LoRA 推断设计了新颖的张量并行策略,以支持大型 Transformer 模型的多 GPU 推断。张量并行是应用最广泛的并行方法,因为它的单程序多数据模式简化了其实施和与现有系统的集成。张量并行可以减少为大模型提供服务时每个 GPU 的内存使用量和延迟。在本文设置中,额外的 LoRA Adapter引入了新的权重矩阵和矩阵乘法,这就需要为这些新增项目制定新的分区策略。
5 评估
最后,研究者通过为 Llama-7B/13B/30B/70B 提供服务来评估 S-LoRA。
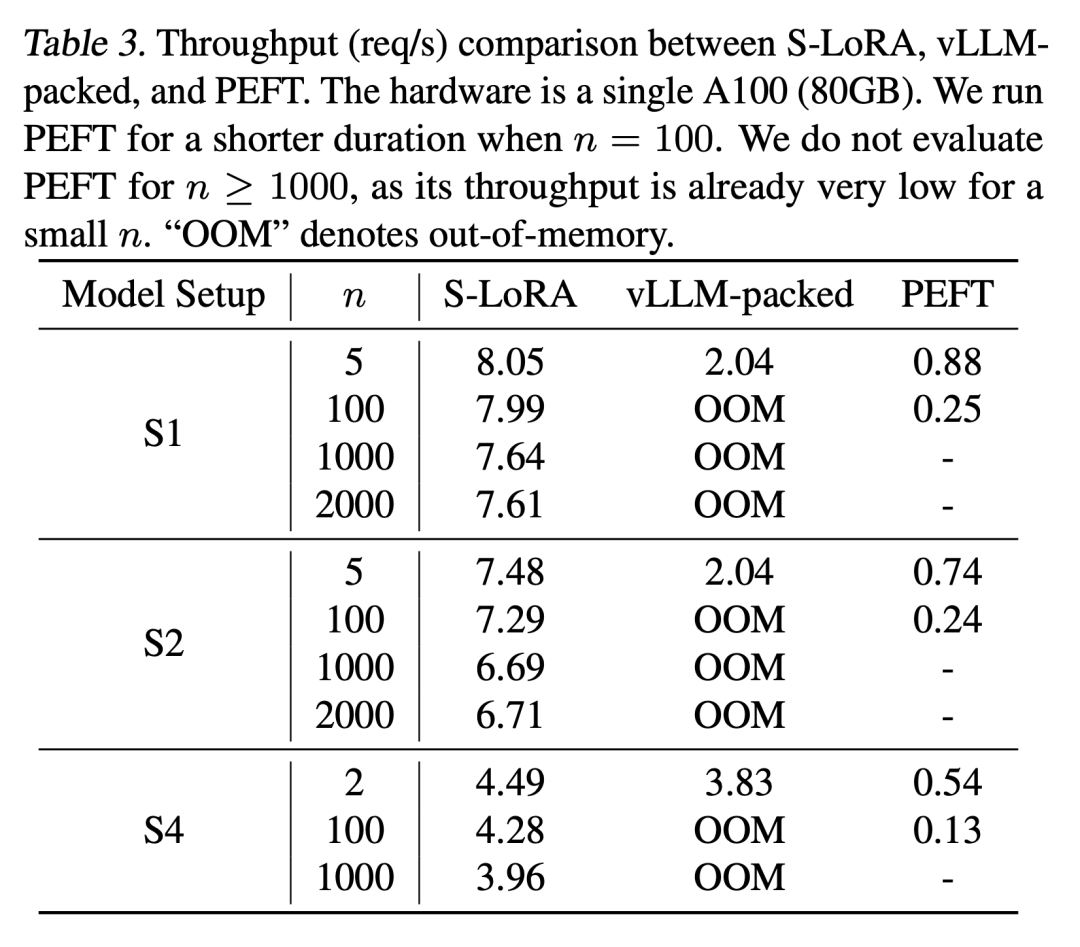
结果表明,S-LoRA 可以在单个 GPU 或多个 GPU 上为数千个 LoRA Adapter提供服务,而且开销很小。与最先进的参数高效微调库 Huggingface PEFT 相比,S-LoRA 的吞吐量最多可提高 30 倍。与使用支持 LoRA 服务的高吞吐量服务系统 vLLM 相比,S-LoRA 可将吞吐量提高 4 倍,并将服务Adapter的数量增加几个数量级。