Skeleton-of-Thought: 思维骨架
Skeleton-of-Thought: 思维骨架
该文 介绍了清华与微软合作提出的一种全新思维骨架(SoT),大大减少了LLM回答的延迟,并提升了回答的质量。
由于当前先进的LLM采用了顺序解码方式,即一次生成一个词语或短语。然而,这种顺序解码可能花费较长生成时间,特别是在处理复杂任务时,会增加系统的延迟。受人类思考和写作过程的启发,来自清华微软的研究人员提出了「思维骨架」(SoT),以减少大模型的端到端的生成延迟。
核心思想:SoT引导LLM,首先生成答案的骨架,然后进行并行API调用或分批解码,并行完成每个骨架点的内容。SoT不仅大大提高了速度,在11个不同的LLM中可达2.39倍,而且还可能在多样性和相关性方面提高多个问题类别的答案质量。研究人员称,SoT是以数据为中心优化效率的初步尝试,揭示了推动LLM更像人类一样思考答案质量的潜力。
1 SoT,让大模型并行解码
1.1 背景
目前,最先进的LLM的推理过程依旧缓慢,交互能力大大减分。LLM推理慢的3个主要原因:
(1)大模型需要大量内存,内存访问和计算。比如,GPT-3的FP16权重需要350 GB内存,这意味着仅推理就需要5×80GB A100 GPU。即使有足够多的GPU,繁重的内存访问和计算也会降低推理(以及训练)的速度。
(2)主流Transformer架构中的核心注意力操作受I/O约束,其内存和计算复杂度与序列长度成二次方关系。
(3)推理中的顺序解码方法逐个生成token,其中每个token都依赖于先前生成的token。这种方法会带来很大的推理延迟,因为token的生成无法并行化。
先前的研究中,大多将重点放在大模型规模,以及注意力操作上。这次,研究团队展示了,现成LLM并行解码的可行性,而无需对其模型、系统或硬件进行任何改动。
研究人员可以通过Slack使用Claude模型将延迟时间从22秒,减少到12秒(快了1.83倍),通过A100上的Vicuna-33B V1.3将延迟时间从43秒减少到16秒(快了2.69倍)。
1.2 思路
这个想法,来源于对人类自身如何回答问题的思考。对于我们来讲,并不总是按顺序思考问题,并写出答案。相反,对于许多类型的问题,首先根据一些策略推导出骨架,然后添加细节来细化和说明每一点。那么,这一点在提供咨询、参加考试、撰写论文等正式场合中,更是如此。我们能够让LLM以同样的方式思考吗?为此,研究人员提出了「思维骨架」(SoT)。具体来说,
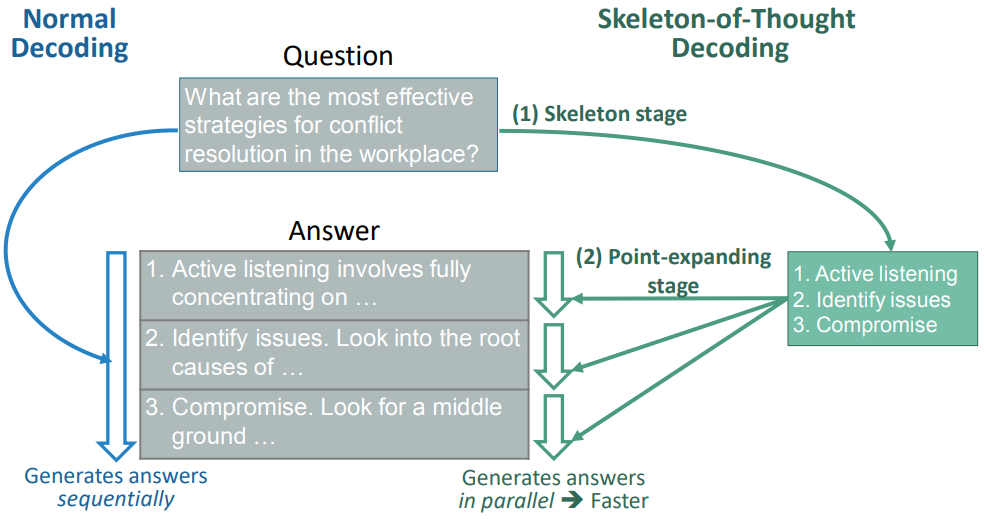
(1)引导LLM首先自己推导出一个骨架。
(2)在骨架的基础上,LLM可以并行地完成每个点,从而提高速度。SoT既可用于加速分批解码的开源模型,也可用于加速并行API调用的闭源模型。
(3)最后,研究人员在最近发布的11个LLM上测试SoT。结果显示,SoT不仅提供了相当大的加速度(最高可达2.39倍) ,而且它还可以在多样性和相关性方面提高几个问题类别的答案质量。
1.3 SoT框架
(1)骨架阶段。
SoT首先使用骨架提示模版,以问题为参数,组装一个骨架请求 。编写骨架提示模板是为了引导LLM输出简洁的答案骨架。然后,研究人员从LLM的骨架答案 中提取B点。
(2)点扩展阶段
基于骨架,让LLM在每个点上平行展开。具体地说,对于带有索引 和骨架 的点,SoT使用 作为LLM的点扩展请求,其中 是点扩展提示模板。最后,在完成所有的点之后,研究人员连接点扩展响应 来得到最终的答案。
如下,Prompt 1和 Prompt 2显示了,研究人员当前实现使用的骨架提示模板图片和点扩展提示模板图片。


(3)骨架提示模板。
为了使输出的骨架简短且格式一致,以提高效率和便于提取要点,骨架提示模板(1)精确描述了任务,(2)使用了两个简单的示范,(3)提供了部分答案「1」为LLM继续写作。
(4)点扩展提示模板。
点扩展提示模板描述点扩展任务,并提供部分答案。研究人员还提供了指示「在1ー2个句子中非常简短地写出」的说明,以便LLM使答案保持简洁。
(5)并行点扩展。
对于只能访问API的专有模型可以发出多个并行的API调用。对于开源模型,让模型将点扩展请求作为批处理。
1.4 为什么SoT降低了解码延迟?
首先要对SoT为什么能够带来显著的端到端加速有一个高层次的理解。为了简单起见,在这里集中讨论点扩展阶段。
具有并行API调用的模型。普通方法向服务器发送一个API请求,而 SoT 并行发送多个 API 请求以获得答案的不同部分。
根据经验,研究人员观察到,在论文中使用的API的延迟与响应中的token数呈正相关。如果请求数量没有达到速率限制,SoT显然会带来加速。
采用批量解码的开源模型。普通的方法只处理一个问题,并按顺序解码答案,而SoT处理多个点扩展请求和一批答案。
2 实验结论
实验数据集:使用Vicuna-80数据集,它由跨越9个类别的80个问题组成,如编码、数学、写作、角色扮演等。
模型:对11个最近发布的模型进行SoT测试,其中包括9个开源模型和2个基于API的模型。
2.1 效率评估
(1)SoT减少不同模型上的端到端延迟
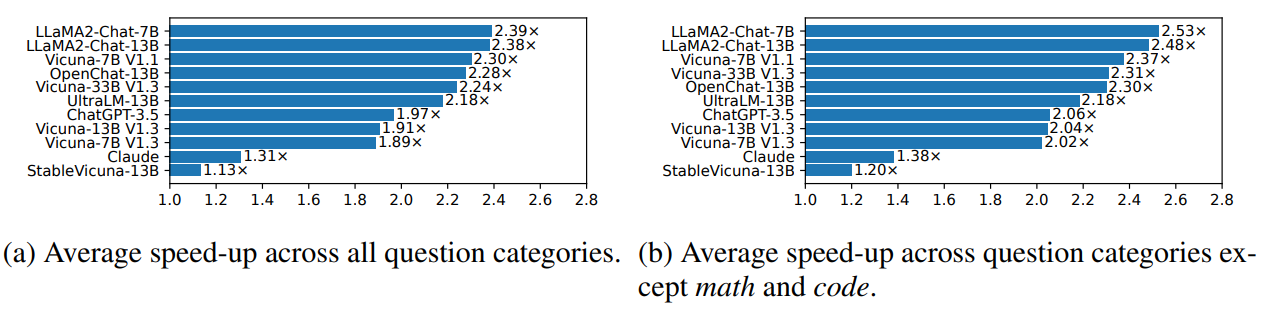
应用SoT后,11个模型中,有6个模型速度有2倍以上的提升(即LLaMA2-Chat-7B,LLaMA2-Chat-13B,Vicuna-7B V1.1,OpenChat-13B,Vicuna-33B V1.3,UltraLM-13B)。在ChatGPT-3.5,Vicuna-13B V1.3和Vicuna-7B V1.3上则有1.8倍以上的速度提升。但在StableVicuna-13B和Claude中,速度几乎没有提升。
如果排除数学和代码的问题类别,速度提升会较排除前略高。
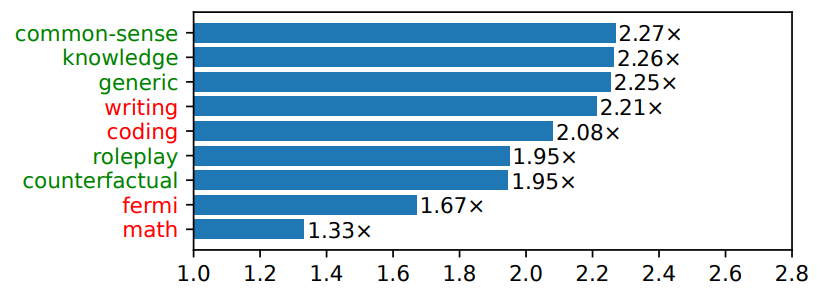
(2)SoT减少不同类别问题的端到端延迟
下图显示了每个问题类别在所有模型中的平均速度提升。那些SoT能够提供高质量答案的问题类别标记为绿色,不能的其他问题类别标记为红色。当前的SoT已经可以提升所有类别问题的速度。但对于那些SoT可以提供高质量答案的5个问题类别(即知识、常识、通用、角色扮演、虚拟情景),SoT可以将整体答案生成过程加速1.95倍-2.27倍。
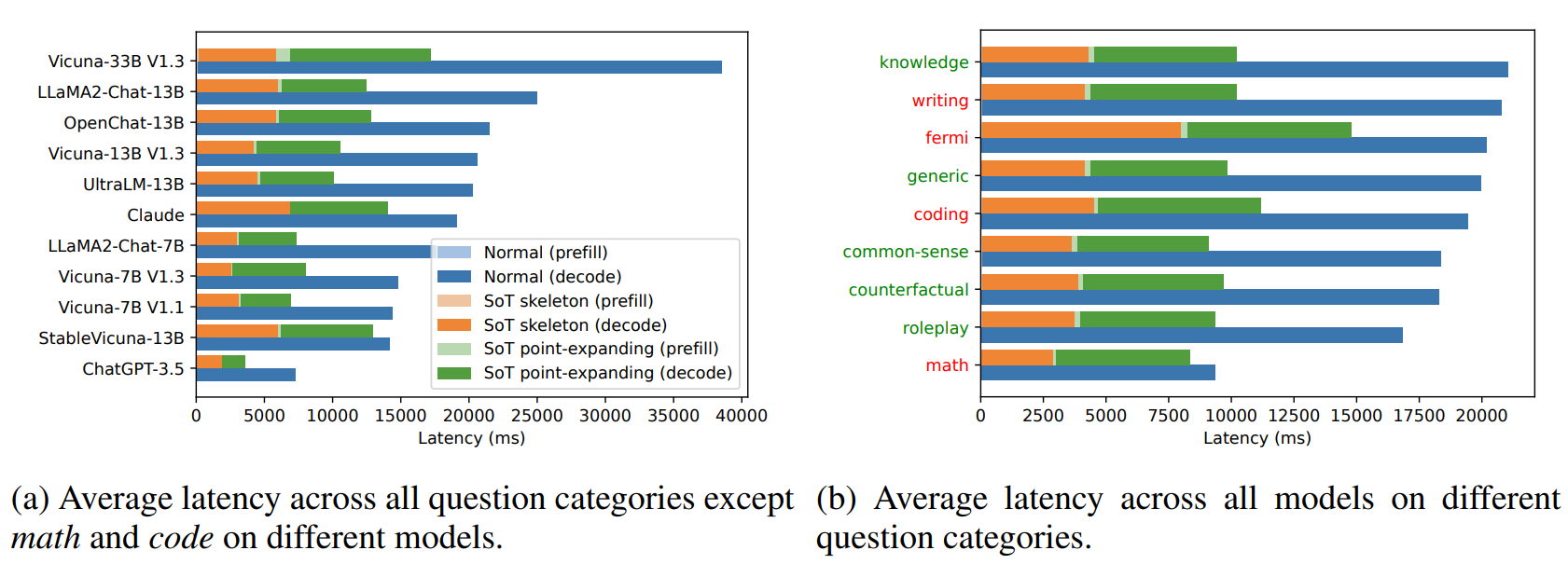
(3) SoT和正常生成的延迟对比
下图显示了模型正常生成和SoT生成的绝对延迟的比较。与正常生成相比,应用SoT的模型生成的速度提升是显而易见的。而解码阶段是内容生成端到端延迟的主要原因。因此,尽管SoT在骨架阶段比正常生成具有较高的预填充延迟,但这对总体延迟和总体速度提升几乎没有影响。
2.2 质量评估
为了比较正常的顺序生成(以下简称为正常)和SoT生成的答案质量,研究采用了两个基于LLM的评估框架: FastChat和LLMZoo。评估过程是向LLM评判器(本研究中为ChatGPT-3.5)展示一个问题和一对答案(由正常和SoT生成),并询问其偏好。回答可能是SoT的答案胜出、与正常答案并列、输给正常答案。
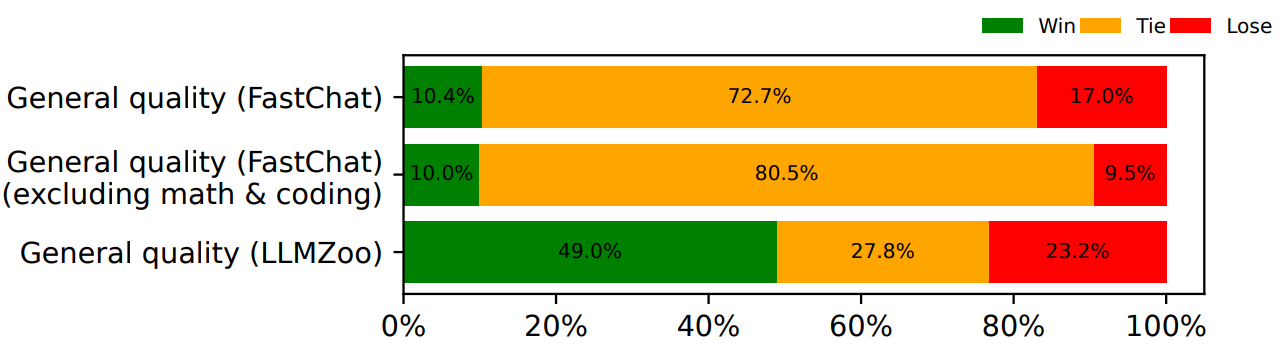
(1)整体质量:
下图显示了使用FastChat和LLMZoo两个指标下使用SOT的模型在所有问题下的赢/平/输率。在SoT严格优于基线时,两个指标之间存在差异(49.0% vs.10.4%)。但这两个指标都认为,在超过76%的情况下,SoT并不比基线(正常生成)差。对于FastChat指标,研究人员还展示了排除数学和编码问题(SoT不适用于这些问题,请参见3.2.2节)的比率:在超过90%的情况下,SoT与基准相当。这表明SoT的答案保持着良好的质量。
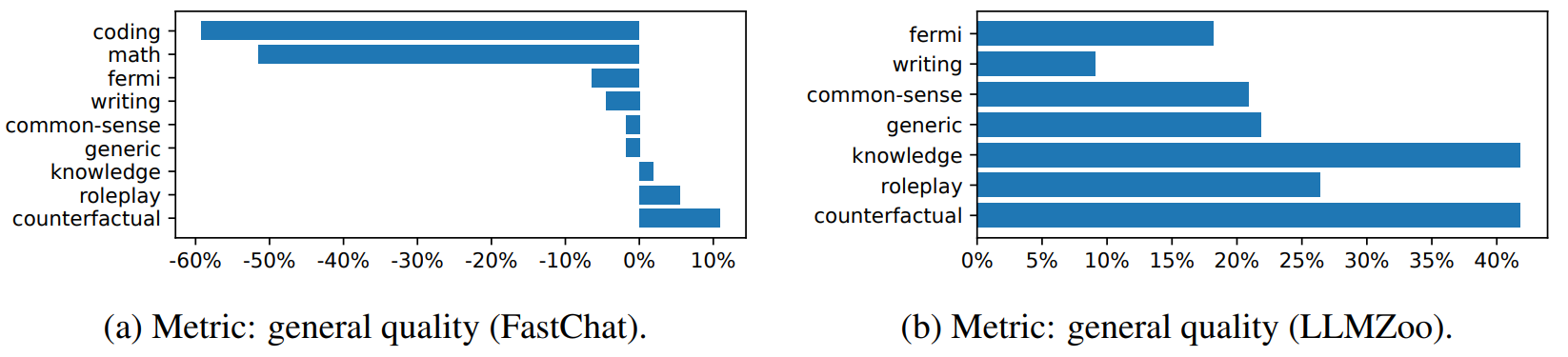
(2)SOT在不同类别问题上的表现
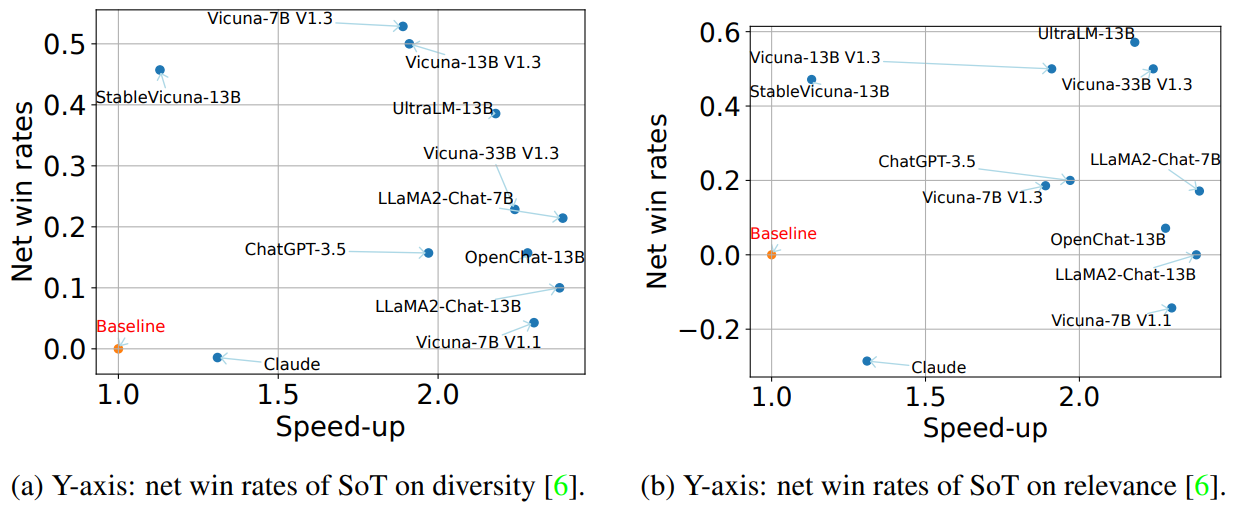
下图计算了所有问题类别的净胜率(胜率-败率)。LLMZoo指标下SoT的质量比FastChat的更好。但不论在哪个框架指标下,SoT在泛型、常识、知识、角色扮演和反事实方面的表现都相对较好,而在写作、费米问题、数学和编码方面表现相对较差。
3 局限性
由于提示集的限制、现有LLM判断的偏差,以及LLM属性评价的内在困难,研究人员目前对LLM问题的答案质量的评价还远不全面。
对更可靠的质量评价而言,扩展提示集,以及用人工评价补充基于LLM的评价非常重要。
然而,目前的研究主要集中在揭示潜在的效率效益上,即通过重新思考现有LLM「全序列解码」的必要性,可以实现相当大的加速。
因此,研究人员在最后将对答案质量的更彻底的评估留给了未来的工作。