Chain-of-Thought: 思维链
Chain-of-Thought: 思维链
该文介绍了 Chain-of-Thought: 思维链 框架,结合 in-context, few-shot prompting 以及多步中间推理,通过大模型来改善数学计算、常识推理的效果。
提示
论文题目:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
作者:Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, Denny Zhou
机构:Google
1 背景介绍
语言模型的本质是对任意一段文本序列的概率进行建模
用一个训练好的大语言模型求解推理任务的几种范式:
1.1 Zero-Shot

这里语言模型的输入就是一道数学题,连接上一个字符串 The answer is,然后让语言模型帮助续写。续写的答案就是80。
1.2 Zero-Shot-CoT
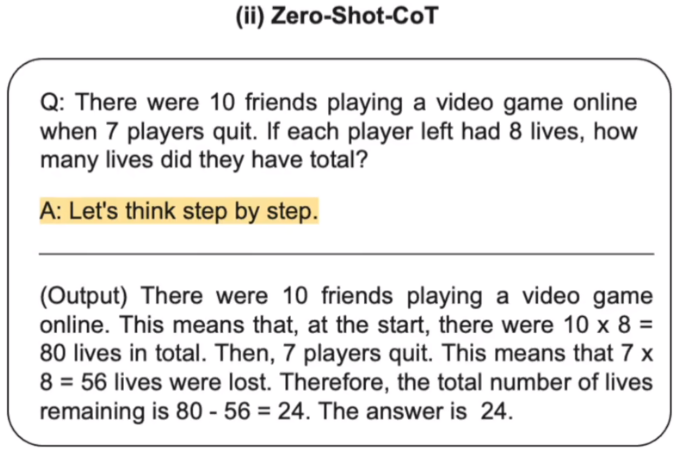
Zero-Shot-CoT 在 Zero-Shot 的基础上增加了一句 Let's think step by step.,大语言模型会自动续写推理过程并得出最后的答案。
1.3 Manual-CoT

在输入问题之前,手动设计一些问题和答案的样例。Manual-CoT 比 Zero-Shot-CoT 的性能要好,因为在输入端提供了问题,推理,答案的样例供参考。然而为了提供这些样例就需要人工设计,这就增加了人工的成本。
1.4 Auto-CoT

如何将人工设计样例的过程自动化?步骤如下:
(1)通过多样性选择有代表性的问题
(2)对于每一个采样的问题,接上 Let's think step by step.,直接丢给语言模型,让它帮我们生成中间推理步骤和答案。然后把所有采样的问题和模型自动生成的推理步骤和答案全部拼接在一起来构成 Few-Shot-Learning 所需要的样例,最后跟上下面需要求解的问题,一起丢给语言模型,让其帮我们续写。
2 思路
结合 in-context, few-shot prompting 以及多步中间推理,通过大模型来改善数学计算、常识推理的效果
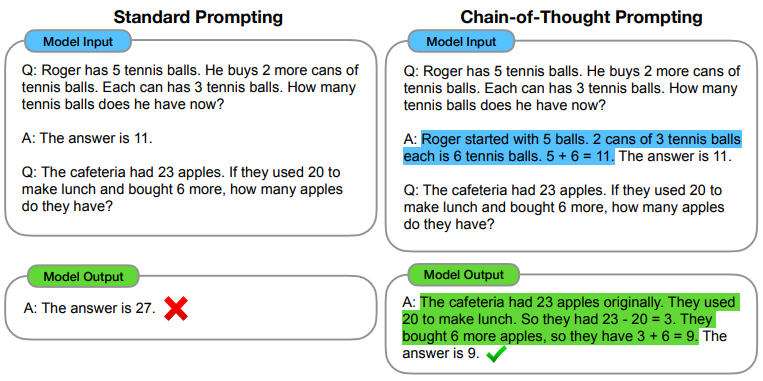
CoT 思维链的灵感来源于人做推理的过程,作者借鉴了这个过程,通过设计类似于思维链来激发大模型,使之拥有推理能力,并且能由于这个有逻辑性的思维链的存在,多步的中间推到可以得到最终的正确答案。

3 实验结果
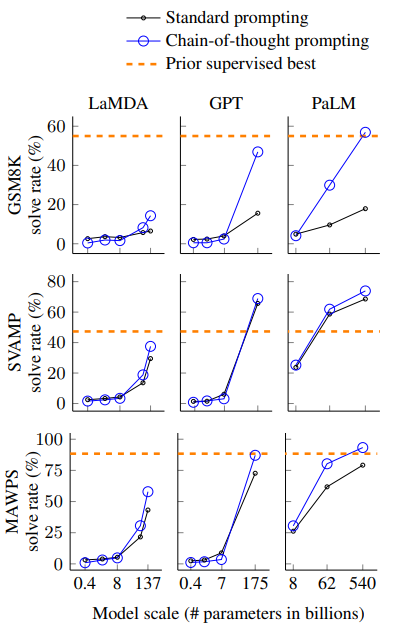
100B(1000亿参数)参数量以下的模型效果不好,侧面反映了他们的instruct fine-tune不够,COT很难激发他的in-context 推理能力。而在100B以上模型效果很好,甚至超过了之前基于监督训练的SOTA模型。