LATS: 将语言模型中的推理、行动和规划统一起来
LATS: 将语言模型中的推理、行动和规划统一起来
LATS是一种利用大型语言模型(LLMs)进行决策的框架,它将LLMs作为代理、价值函数和优化器,以增强决策能力。LATS采用蒙特卡罗树搜索作为模型,利用外部反馈的环境提供更加灵活和适应性的问题解决机制。LATS在HumanEval上使用GPT-4实现了94.4%的编程得分,在WebShop上使用GPT-3.5实现了平均得分75.9。
提示
论文题目:Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
作者:Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, Yu-Xiong Wang
机构:University of Illinois at Urbana-Champaign
1 介绍
LLMs不仅在标准的自然语言处理任务上表现出色,还被应用于需要高级常识推理或量化技能的任务。LLMs还能在涉及知识和推理的复杂环境中表现出色,如网络导航、工具使用或开放式游戏。一些方法通过外部反馈或观察来增强LLMs的推理和行动能力,但这些方法缺乏人类的深思熟虑的决策特征。最近的搜索引导LLM方法通过搜索多个推理链来解决这个问题,但这些方法在孤立的情况下运行,不包括可以改善推理的外部反馈。
LATS是一个用于决策和推理的语言模型框架,通过在可能的推理和行动步骤的组合空间上进行搜索,将LLM规划、行动和推理策略统一起来。LATS利用预训练的LLM作为代理、价值函数和优化器,利用现代LLM的强大自然语言理解和上下文学习能力,使用文本作为框架各组件之间的接口,使LATS能够根据环境条件自适应规划,而无需额外训练。LATS是首个将推理、行动和规划结合起来增强LLMs的框架。LATS在HotPotQA和WebShop上的性能超过了ReAct,并在HumanEval上取得了最先进的结果。LATS通过LM的启发式指导,引入了基于LM的蒙特卡洛树搜索变体,从采样的动作中构建最佳轨迹,实现了比反射式提示方法更灵活和适应性更强的问题解决。LATS通过整合外部反馈和自我反思,增强了模型的感知能力,并使代理能够从经验中学习,超越了基于推理的搜索方法。通过在编程、交互式QA和网页导航等不同领域的实验,我们展示了LATS在利用LLMs进行自主推理和决策方面的多样性。
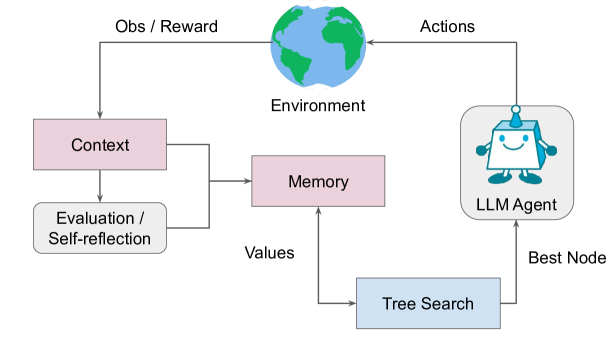
在中心是LLM Agent,也就是语言模型,它起到整个系统的核心作用。左边是一个 Tree Search 模块,这实现了蒙特卡罗树搜索,用来有效地构建推理路径,实现决策规划。右边是Environment,也就是外部环境。Agent可以在这个环境中进行交互,产生 Actions 和收到 Observations。Agent 和 Environment 通过文本的形式进行交互,这样可以利用语言模型本身优秀的自然语言理解能力。在 Agent 内部引入了Context Memory,可以存储之前的语境,用于之后的决策更新。还有一个 Self-reflection 模块,当遇到失败情况时,可以提供文本反馈,指出错误原因并给出改进建议。整个系统的目标是利用语言模型本身的知识表达、推理和补全的能力,在与外部环境交互的过程中,通过误差学习、决策树搜索等方式进行自我完善,实现可靠的决策。最终找到 the Best Node,也就是推理/决策路径中最佳的节点,产生 model 输出。
2 和类似工作的对比
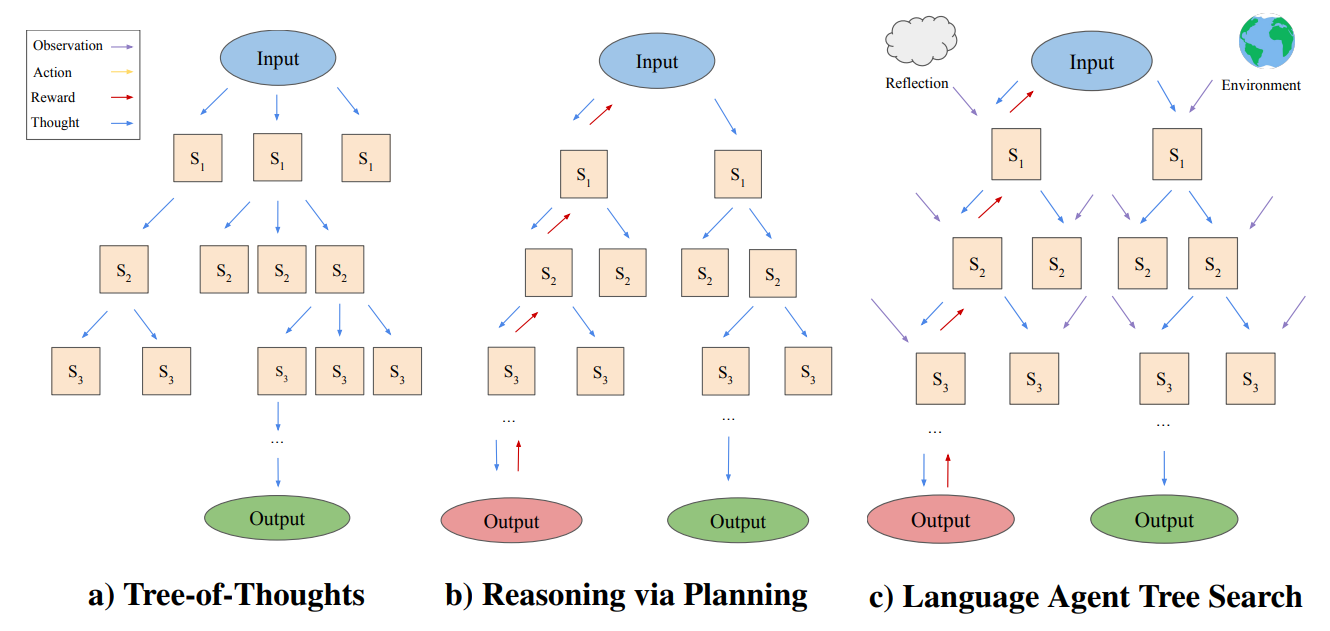
ToT和RAP仅依赖于语言模型的内部知识进行状态扩展和评估。而LATS引入了环境(Environment)的反馈。
通过与外部环境的交互,LATS可以获得额外的观察和奖励信号,这些信号指导树搜索过程,并可用于增强语言模型的感知能力,避免事实hallucination(事实幻觉)。
ToT和RAP使用简单的搜索算法(BFS、DFS等),而LATS采用了更具原则性的蒙特卡洛树搜索,可以更好地平衡exploration和exploitation。
LATS还引入了自我反思(Self-Reflection)模块,语言模型可以从反思和经验中学习,不需要额外的训练优化。这种自我完善的能力也是ToT和RAP所没有的。
综上,LATS是一个更为完整和统一的框架,它协同了规划、推理和行动三者的能力,可以更好地把语言模型作为决策代理开发和应用到复杂任务中。
3 统一规划、推理和行动
3.1 大预言模型智能体(LLM Agent)
LATS是基于ReAct的支持顺序推理或决策任务的模型。该模型使用LM作为基础决策者,并通过采样多个动作来构建最佳轨迹。这种方法可以在决策和推理空间中进行更大的探索。
3.2 LATS
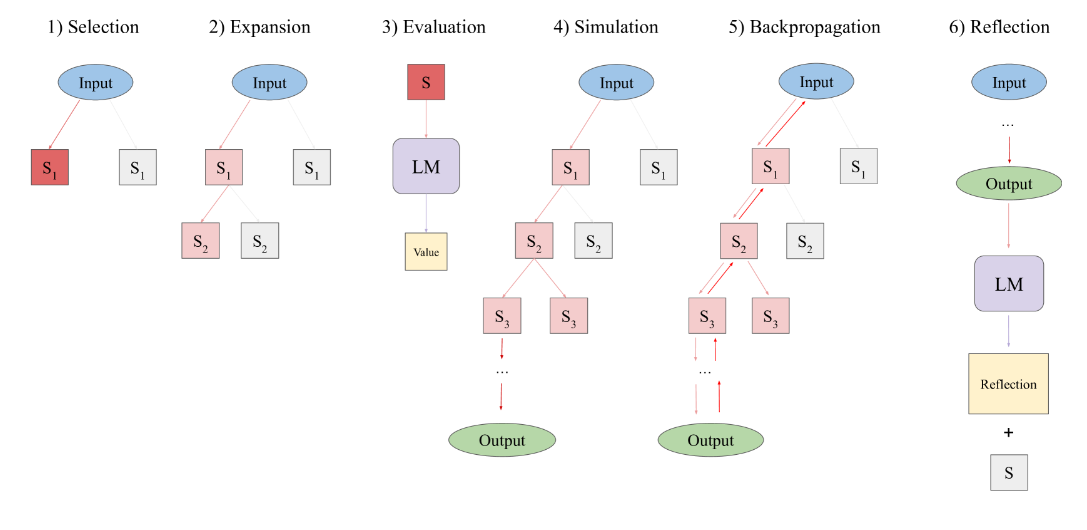
- Selection(选择):使用UCT算法基于价值和访客次数选择树中最适合扩展的节点。从根节点开始,在每一层上选择UCT值最高的子节点,直到达到叶节点。
- Expansion(扩展):在选定要扩展的叶子节点上,使用语言模型pθ根据当前状态采样n个可能的操作。每个操作会影响环境并返回一个观察结果。这就添加了n个新的子节点到树中。
- Evaluation(评估):使用语言模型pV对新增的每个子节点进行标量评分,反映解决方案的进展程度。这些评分用作启发式信息来指导搜索算法。
- Simulation(模拟):从当前选择的节点开始扩展,采样高评分的节点直到达到终止节点,为整个解决方案轨迹提供反馈。
- Backpropagation(反向传播):使用模拟结果更新沿途所有节点的评分,为后续选择提供更好的估计。
- Reflection(反思):如果轨迹失败,使用语言模型p_{ref}生成文本反思,总结错误并提出改进建议。这些反思存储并用于增强代理。
这些操作循环执行,直到完成任务或达到计算预算。LATS通过搜索、环境交互和反思协同工作,以增强语言模型的推理和决策能力。
4 实验
本文介绍了LATS方法在不同决策领域的应用。这些领域包括编程、HotPotQA和WebShop。LATS方法结合了推理和行动能力,具有广泛的适用性。
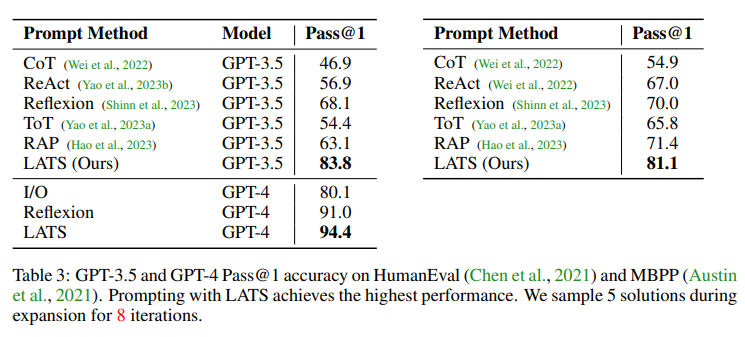
本文研究了在编程任务中使用外部观察的重要性,通过在Humaneval和MBPP数据集上评估基线和LATS的表现,发现搜索和语义反馈对于更好的性能至关重要。LATS在两个数据集上的表现最好,RAP使用类似的搜索算法,也表明了外部反馈对于困难的推理任务(如编程)的重要性。使用LATS和GPT-4在HumanEval数据集上取得了最好的表现。
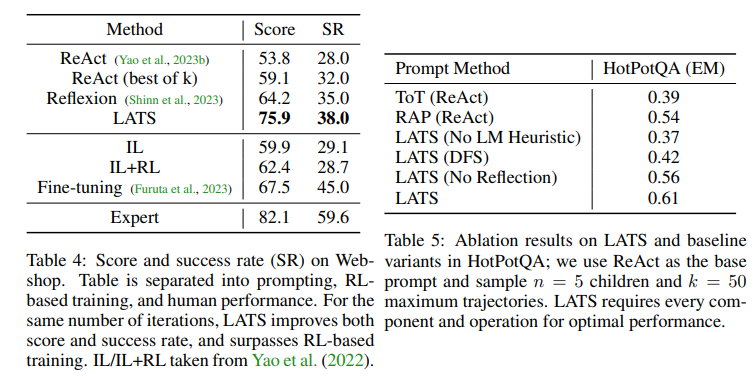
本文研究了在HotPotQA数据集上使用内部推理和外部检索策略的表现。现代LLMs已经编码了事实知识,可以直接回答问题。搜索方法ToT和RAP可以采样和探索更多输出,对需要推理的问题有更大的提升。LATS比ReAct表现更好,即使采样相同数量的轨迹,通过扩展更多节点进行有原则的搜索。在内部推理方面,LATS与RAP相当,但表现不如行动。将内部和外部推理结合起来,LATS的表现最好,表明外部反馈在增强推理方面的重要性。
本文介绍了一个复杂的决策环境WebShop,它是一个在线购物环境,由一个包含1.18M真实产品和12k人类指令的网站组成。文章使用预构建的搜索和点击命令以及浏览器反馈和反思作为观察。通过平均得分和成功率两个指标来评估性能。结果表明,GPT-3.5与ReAct在WebShop中表现出与模仿学习相当的竞争力,并且可以超越强提示策略的强化学习技术。使用LATS可以显著提高性能,表明它可以在相同的迭代次数下实现更有效的探索。
5 总结
这项工作介绍了语言代理树搜索(LATS)框架,它是第一个将规划、行动和推理统一起来以增强LLM问题解决能力的框架。通过使用搜索算法有意构建轨迹、整合外部反馈并使代理能够从经验中学习,LATS解决了之前提示技术的关键限制。我们的评估证明了LATS利用LLM能力在各种决策任务中的能力,同时保持其推理能力而无需额外训练。搜索、交互和反思之间的协同提供了一种多功能的自主决策方法,突显了LLM作为通用代理的潜力。