THOR:思维链激励下的隐式情绪推理
THOR:思维链激励下的隐式情绪推理
本文介绍利用思维链方法来链式推理出隐式情感的方法,在 Zero-shot 设定下提升 50% F1 值。

论文链接:
https://aclanthology.org/2023.acl-short.101.pdf
https://github.com/scofield7419/THOR-ISA
1 前言
情感分析(Sentiment Analysis, SA)是自然语言处理领域一个较为火热的研究方向,该任务旨在检测输入文本中对给定目标的情感极性。其中,根据情感特征词是否给定,情感分析又可分为显式情感分析(Explicit SA,ESA)和隐式情感分析(Implicit SA,ISA)。在ISA中,观点线索以一种隐含和模糊的方式呈现。因此,检测隐含情感需要常识和多跳推理能力,以推断出观点的潜在意图。受思维链(Chain of Thought,CoT)的启发,引入了一个三跳推理(THOR)CoT框架,以模拟人类类似的隐含情感推理过程。

与ESA不同,ISA更具挑战性,因为在ISA中,输入只包含事实描述,没有直接给出明确的观点表达。例如,对于给定的文本“ Try the tandoori salmon!",几乎所有现有的情感分类器都会预测对“坦多利三文鱼”中性情感,因为没有明显的线索词。人类可以轻松准确地确定情感状态,因为我们总是抓住文本背后的真实意图或观点。因此,传统的情感分析方法在理解情感如何引发方面是无效的。
实际上,首先发现隐藏的观点背景对于实现准确的ISA至关重要。对于图1.1中的Case#1,捕捉整体情感是轻而易举的,因此可以准确地推断出对给定目标酒店的积极极性。受到这种细致入微的情感精神的启发,我们考虑挖掘隐含的方面和观点状态。对于图1.1中的Case#2,如果模型可以首先推断出关键情感成分,例如潜在的方面“ taste”,潜在的观点"good and worth trying",最终极性的推断难度将大大减轻。为了实现这一目标,常识推理能力和多跳推理能力是不可或缺的。
2 方法
情感分析任务(无论是ESA还是ISA)的定义如下:给定一个包含目标词的句子,模型确定句子的情感极性,即正面、中性或负面。对于标准的基于提示的方法,构建以下提示模板作为LLM的输入: "Given the sentence _ what is the sentiment polarity towards? "

2.1 原理
根据上述分析我们可以归纳出以下几点重要方面。
- ISA 的决策依赖于一个步步推理的过程,需要一步一步地去揭示更多的上下文、隐含信息。相比之下,现有的(传统的)SA 方法往往采用找关键词并一步到位的预测方式,自然是行不通的。
- 这个推理过程实际上完美地对应了现有的细粒度方面级别情感分析(Aspect-based Sentiment Analysis, ABSA)的定义,即先确定方面(Aspect),再挖掘意见(Opinion),最终得到情感极性(Polarity)。其中中间的 Aspect 与 Opinion 是隐式的,需要通过推理得到,才能构成完整的情感版图。
- 这个推理过程可以更确切地拆分为两种推理能力:一个是常识推理能力,另一个是多跳推理能力。
2.1 思维链提示
图2.1给出了一个 THOR 的完整框架示意图。在这里事先定义好输入的句子为X,给定t为待分析的目标,极性为y,并且定义中间的Aspect为A和潜在的Opinion表达为O。构建了一种三跳 Prompt 模板,具体如下。
**第一步:**首先询问 LLM 句子中涉及到关于哪一种方面a,使用以下模板。

**第二步:**现在基于X、t和A,要求 LLM 详细回答关于提到方面A的潜在观点O是什么。

**第三步:**在完整的情感框架(X、t、A和O)作为上下文的基础上,我们最终要求LLM 推断出极性t的最终答案。

2.2 增强推理能力
进一步利用自洽性机制来巩固推理的正确性。具体而言,对于每一个推理步骤,将LLM解码器设置为生成多个答案,其中每个答案可能会给出不同的目标、观点以及极性的预测。在每一步中,保留高一致性的投票的答案作为下一步的上下文。
当有可用的训练集时,还可以对THOR进行微调,即有监督的微调设置。论文设计了一种推理修订方法。技术上,在每一步中,通过连接以下内容构建提示:1)初始上下文,2)这一步的推理答案文本,以及3)最终的问题,并将其输入LLM中,以预测情感标签,而不是进行下一步的推理。
3 实验
3.1 监督微调的结果

3.2 零样本推理的结果
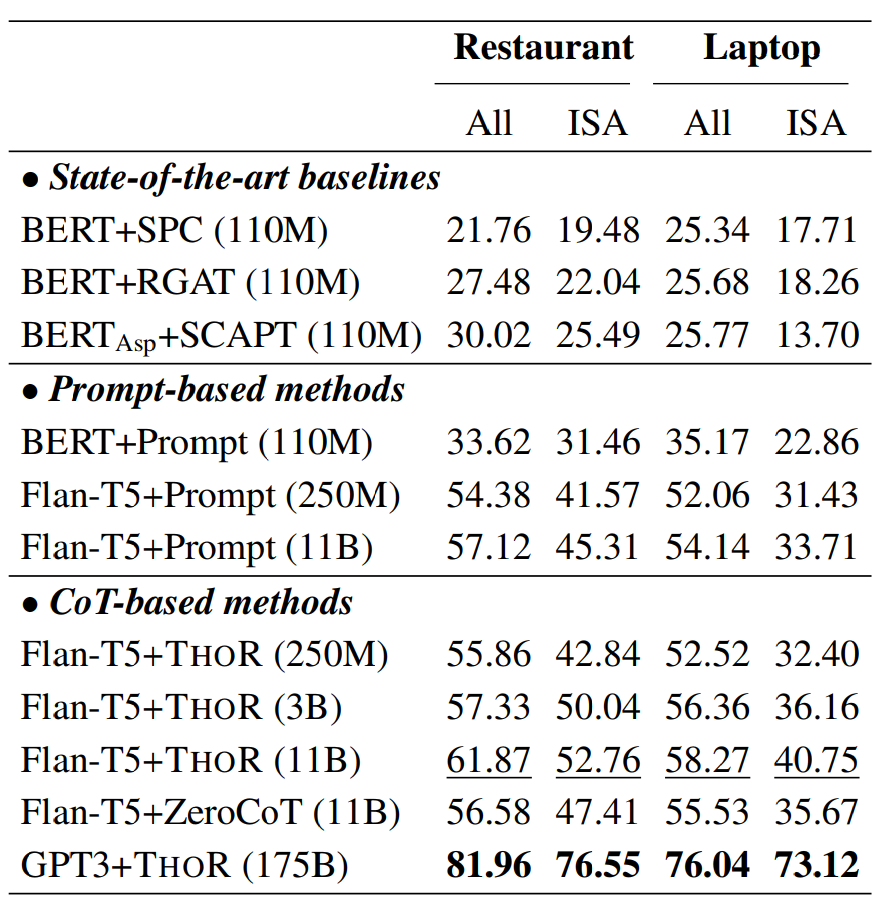
3.3在ChatGPT上的表现
在图3.1中,GPT3 和 ChatGPT 利用 THOR 都在 ISA 上取得了显著的改进。同时发现,在 ESA 上的提升不是很明显。

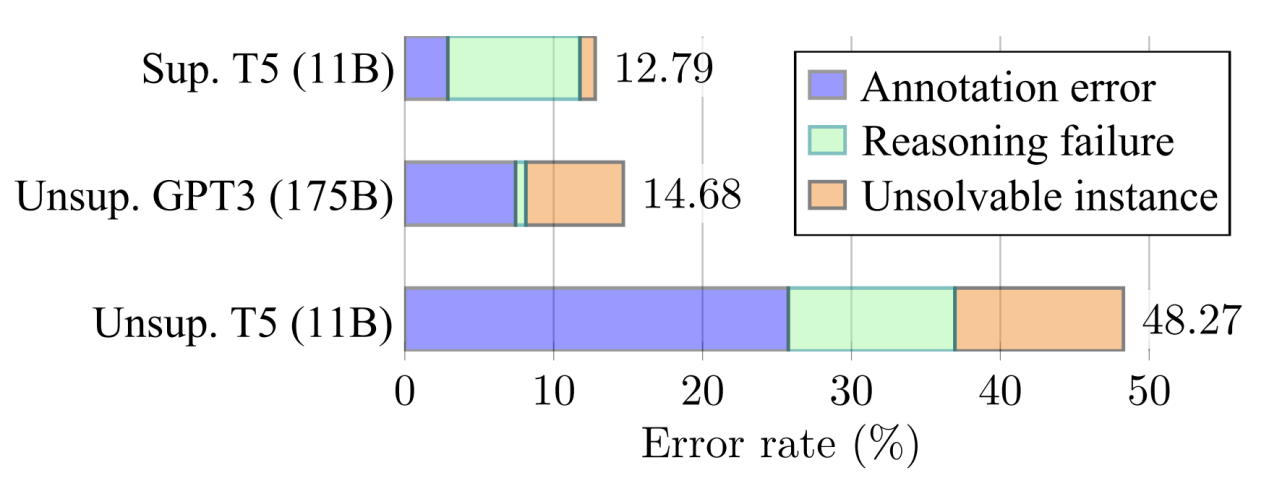
3.4 误差分析
在图3.2中,展示了使用THOR时失败案例的错误率,共分为三种错误类型。Flan-T5-11B LLM在零样本设置下的错误率为48.27%,而在受监督的情况下降至12.79%。无监督的GPT3(175B)在错误率上与受监督的T5相似,而后者在推理能力不足的情况下更频繁地失败。与有监督的T5相比,无监督的GPT3中大部分失败来自问题数据注释。由于有监督的T5是在'false'标签的监督下进行微调的,它实际上可能会学习到虚假的相关性,但测试精度更高。
4 结论
本文介绍了一种三跳推理学习框架(THOR)用于解决隐式情感(ISA)任务,通过步步递进式、由易到难的渐进推理诱导 LLM 得到丰富的中间上下文信息帮助推断情感极性。所提出的 THOR 框架基于思维链(CoT)提示学习方法,继承了其简单实现的特点,而可实现高性能的任务提升。
今年随着 LLM 的爆裂式发展,目前 NLP 社区已经翻开了新的篇章。LLM 已经为 NLP 各个方面的基准任务提出了新的层面的要求,比如,向更难、更复杂、更接近人级别(Human-level)的语言理解能力的方向发展。其中 CoT 方法得到了较多的关注,其帮助 LLM 实现类人的多跳推理过程。
目前 CoT 大部分工作主要关注于解决数学逻辑方面的离散推理任务,而据我们所知,这是第一次成功将 CoT 思想扩展到情感分析领域这种非数字逻辑推理的任务。未来探索可以将 CoT 的思路扩展到更多的类似的应用上,比如设计并结合更合适的 In-context demonstration 来更好地诱导中间推理过程。