Tree-of-Thought: 思维树
Tree-of-Thought: 思维树
该文介绍了 Tree-of-Thought: 思维树 框架,由普林斯顿和谷歌DeepMind联合提出的全新「思维树」框架,让GPT-4可以自己提案、评估和决策,推理能力最高可提升1750%。
思维树可以让 LLM:
(1)自己给出多条不同的推理路径
(2)分别进行评估后,决定下一步的行动方案
(3)在必要时向前或向后追溯,以便实现进行全局的决策
论文实验结果显示,ToT 显著提高了 LLM 在三个新任务(24点游戏,创意写作,迷你填字游戏)中的问题解决能力。比如,在24点游戏中,GPT-4 只解决了 的任务,但 ToT 方法的成功率达到了 。
1 让LLM反复思考
用于生成文本的大语言模型 GPT、PaLM,现已经证明能够执行各种广泛的任务。所有这些模型取得进步的基础仍是最初用于生成文本的 自回归机制,以从左到右的方式一个接一个地进行 token级的决策。
这样一个简单的机制能否足以建立一个通向解决通用问题的语言模型?如果不是,哪些问题会挑战当前的范式,真正的替代机制应该是什么?
关于人类认知的文献中对于双重过程模型的研究表明,人类有两种决策模式:
(1)系统1 - 快速、自动、无意识模式。
(2)系统2 - 缓慢、深思熟虑、有意识模式。
语言模型简单关联 token 级选择可以让人联想到系统1,因此这种能力可能会从系统2规划过程中增强。系统1可以让 LLM 保持和探索当前选择的多种替代方案,而不仅仅是选择一个,而系统2评估其当前状态,并积极地预见、回溯以做出更全局的决策。
这个观点突出了现有使用LLM解决通用问题方法的2个主要缺点:
(1)局部来看,LLM 没有探索思维过程中的不同延续——树的分支。
(2)总体来看,LLM 不包含任何类型的计划、前瞻或回溯,来帮助评估这些不同的选择。
为了解决这些问题,研究者提出了用语言模型解决通用问题的思维树框架(ToT),让 LLM 可以探索多种思维推理路径。
2 ToT四步法
现有的方法,如 IO、CoT、CoT-SC,通过采样连续的语言序列进行问题解决。而 ToT 主动维护了一个思维树。每个矩形框代表一个思维,并且每个思维都是一个连贯的语言序列,作为解决问题的中间步骤。
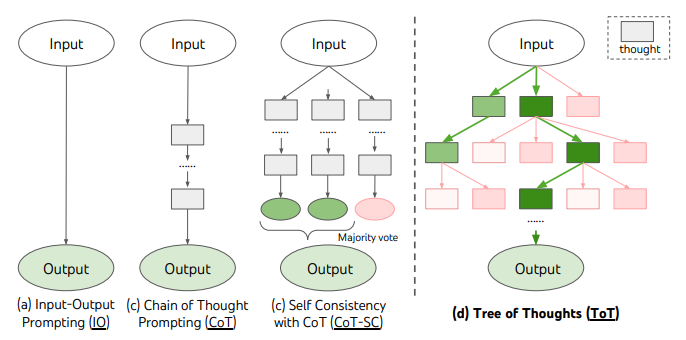
ToT 将任何问题定义为在树上进行搜索,其中每个节点都是一个状态 ,表示到目前为止输入和思维序列的部分解。ToT 执行一个具体任务时需要回答4个问题:
(1)如何将中间过程分解为思维步骤;
(2)如何从每个状态生成潜在的想法;
(3)如何启发性地评估状态;
(4)使用什么搜索算法。
2.1 思维分解
CoT 在没有明确分解的情况下连贯抽样思维,而 ToT 利用问题的属性来设计和分解中间的思维步骤。
根据不同的问题,一个想法可以是几个单词(填字游戏) ,一条方程式(24点) ,或者一整段写作计划(创意写作)。
一个想法应该足够小,以便 LLM 能够产生有意义、多样化的样本。但一个想法也应该大,足以让 LLM 能够评估其解决问题的前景。
2.2 思维生成器
给定树状态 ,通过2种策略来为下一个思维步骤生成 个候选者。
(1)从一个CoT提示采样思维,,在思维空间丰富(比如每个想法都是一个段落),并且导致多样性时,效果更好。
(2)使用 proposal prompt 按顺序提出想法,,这在思维空间受限制(比如每个思维只是一个词或一行)时效果更好,因此在同一上下文中提出不同的想法可以避免重复。
2.3 状态求值器
给定不同状态的前沿,状态评估器评估它们解决问题的进展,作为搜索算法的启发式算法,以确定哪些状态需要继续探索,以及以何种顺序探索。
虽然启发式算法是解决搜索问题的标准方法,但它们通常是编程的(DeepBlue)或学习的(AlphaGo)。这里,研究者提出了第三种选择,通过LLM有意识地推理状态。
在适用的情况下,这种深思熟虑的启发式方法可以比程序规则更灵活,比学习模型更有效率。与思维生成器,研究人员也考虑2种策略来独立或一起评估状态:对每个状态独立赋值;跨状态投票。
2.4 搜索算法
最后根据树的结构,使用插件化的方式使用不同的搜索算法。
(1) 算法1——广度优先搜索(BFS),每一步维护一组最有希望的状态。
(2) 算法2——深度优先搜索(DFS),首先探索最有希望的状态,直到达到最终的输出 ,或者状态评估器认为不可能从当前的为阈值解决问题。在这两种情况下,DFS都会回溯到 的父状态以继续探索。

由上,LLM通过自我评估和有意识的决策,来实现启发式搜索的方法是新颖的。
3 实验

为此,团队提出了三个任务用于测试——即使是最先进的语言模型GPT-4,在标准的IO提示或思维链(CoT)提示下,都是非常富有挑战的。
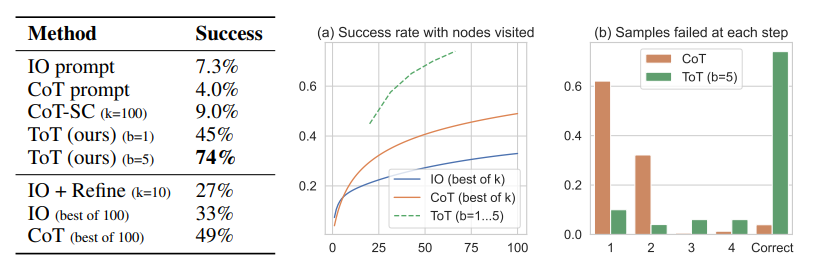
IO,CoT和CoT-SC提示方法在这几项任务上的表现不佳,成功率仅为 ,和。相比之下,ToT在广度为 b = 1 时已经达到了 的成功率,而在 b = 5 时达到了 。同时还考虑了 IO/CoT 的预测设置,通过使用最佳的 个样本()来计算成功率,CoT比IO扩展得更好,最佳的100个CoT样本达到了的成功率,但仍然比在ToT中探索更多节点()要差。