复杂知识库问答综述
复杂知识库问答综述
本文介绍东南大学发表的一篇关于KBQA的论文综述,详细介绍了复杂事实性问题的处理框架。
提示
论文题目:Complex Knowledge Base Question Answering: A Survey
作者:Yunshi Lan, Gaole He, Jinhao Jiang, Jing Jiang, Wayne Xin Zhao, Ji-Rong Wen
机构:东南大学
1 前言
大模型落地应用过程中,一般形式还是问答形式,靠问答来解决一系列问题。无论是要求大模型给出具体的专业化知识,还是要求大模型进行某项作业的开展,都是以问题(指令其实也是一种特殊的问题)的形式进行。所以在RAG中,如何将问题转化为大模型能够理解的问题,转化为各种知识库可以查询的问题,这是应用大模型能力的关键。本篇主要讲述了KBQA中基于语义解析的方法(SP-base)和基于信息检索的方法(IR-base)。
2 基于语义解析的方法
基于SP的方法采用一种解析-执行过程,通过一系列模块来实现,包括问题理解、逻辑解析、知识库连接和知识库执行。这些模块在处理复杂的知识库问答(KBQA)时面临不同的挑战。首先,当问题在语义和句法方面都较为复杂时,问题理解变得更加困难。其次,逻辑解析必须涵盖复杂问题的多种查询类型。此外,涉及更多关系和主题的复杂问题将显著增加解析的可能搜索空间。而且逻辑形式的手动标注成本高昂且劳动密集,使用弱监督信号(即问题-答案对)来训练基于SP的方法具有挑战性。在接下来的部分中,我们将介绍先前研究如何应对这些挑战,并总结它们提出的高级技术。
2.1 理解复杂的语义和句法结构
作为基于SP方法的第一步,问题理解模块将非结构化文本转化为编码的问题,这有助于下游的解析过程。与简单问题相比,复杂问题具有组合语义和更复杂的查询类型,这增加了语言分析的难度。
将问题的结构属性纳入到seq2seq生成中 许多现有方法依赖于句法分析,例如依赖关系和抽象含义表示(AMR),以提供问题成分与逻辑形式元素(如实体、关系、实体类型和属性)之间更好的对齐。这一研究方向在图2.2的左侧有所示。其好处有两个方面:(1)AMR在消除自然语言表达中的歧义方面很有效。(2)AMR解析模块高度抽象,有助于以与知识库无关的方式理解问题。然而,在复杂问题上,尤其是在存在长距离依赖的情况下,产生句法分析仍然不够让人满意。
将逻辑形式的结构属性纳入特征化排名中 通过分析复杂语义来理解问题非常重要。同样,分析查询的句法结构也至关重要,确保生成的逻辑形式能够满足复杂查询的句法要求。虽然上述方法使用Seq2seq框架生成逻辑形式,但另一条研究路线(如图2.2的右侧所示)侧重于利用结构属性(例如逻辑形式的树结构或图结构)来对候选解析进行排名。
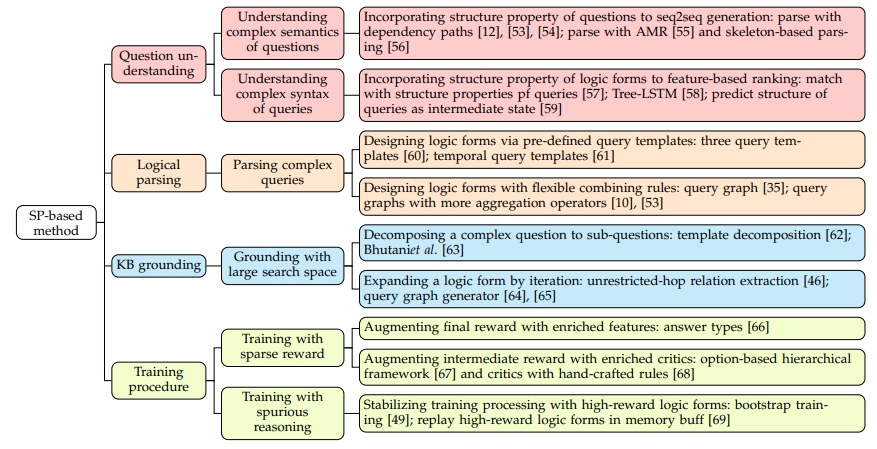
2.2 解析复杂查询
为了生成可执行的逻辑形式,传统方法首先利用现有的解析器将问题转化为CCG推导,然后通过将谓词和参数与知识库中的关系和实体进行对齐,将其映射到SPARQL。由于本体不匹配问题,这种方法对于复杂问题来说是次优的。因此,为了进行准确的解析,需要利用知识库的结构,在解析过程中进行与知识库的连接。
2.3 在庞大的搜索空间下进行知识库连接
为了获得可执行的逻辑形式,知识库连接模块会将可能的逻辑形式与知识库进行实例化。由于知识库中的一个实体可能与数百甚至数千个关系相连,考虑到计算资源和时间复杂性,枚举和连接复杂问题的所有可能逻辑形式是不可行的。
**将复杂问题分解为子问题 **研究人员尝试提出方法,通过多个步骤生成复杂查询,而不是通过单一遍历来枚举逻辑形式。将复杂问题分解为多个简单问题,其中每个简单问题都被解析为一个简单的逻辑形式,最终答案可以通过部分逻辑形式的连接或合成来获得。这种分解-执行-连接策略可以有效缩小搜索空间。
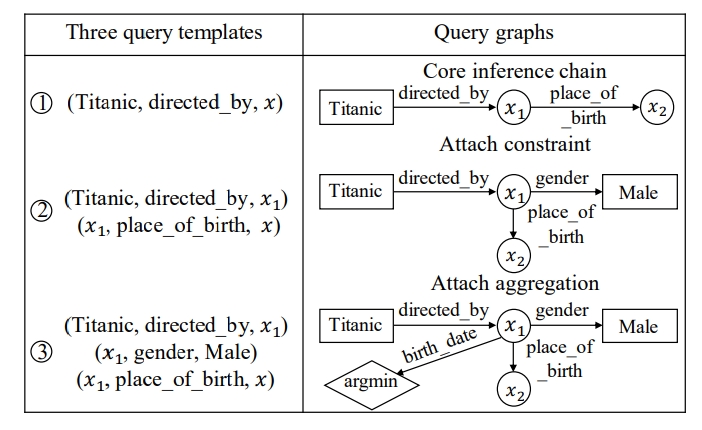
迭代查询 与将复杂问题分解为子问题不同,许多研究采用了扩展和排名策略,通过迭代方式扩展逻辑形式以减少搜索空间。具体而言,它们首次收集了与主题实体的1跳邻域相关的所有查询图作为第一次迭代的候选逻辑形式。这些候选根据它们与问题的语义相似性进行排名。排名靠前的候选保留下来进行进一步扩展,而排名靠后的候选则被过滤掉。在随后的迭代中,每个排名靠前的查询图都会进行扩展,从而产生了一组更复杂的候选查询图。此过程将一直重复,直到获得最佳查询图。
2.4 在弱监督信号下进行训练
为了应对未标记的推理路径问题,已经使用基于强化学习(RL)的优化方法来最大化预期奖励。通过RL进行训练表明,基于SP的方法只能在完整解析逻辑形式之后才能获得反馈。这导致了一个具有极度稀疏正奖励的长时间探索阶段。为了解决这个问题,提出了一些方法来增强最终奖励或中间奖励。
3 基于信息检索的方法
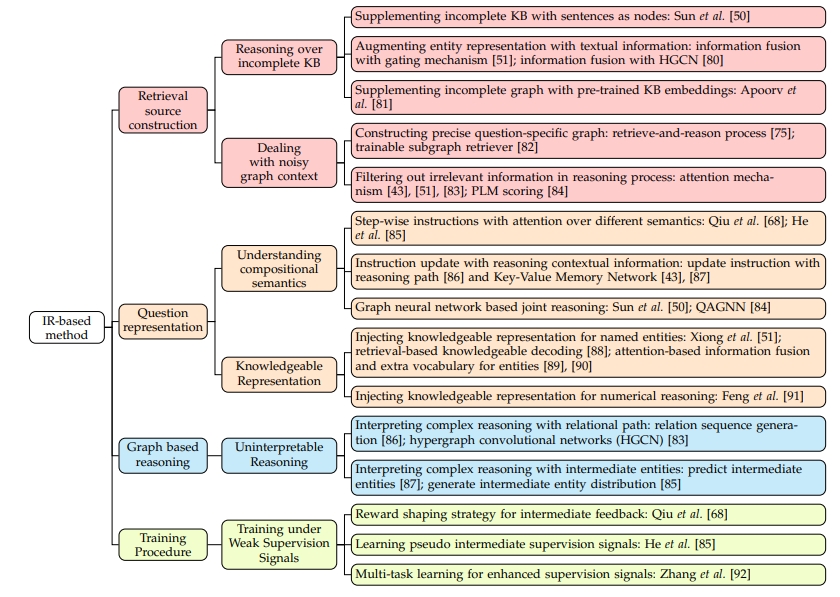
整个流程通常包括检索源构建、问题表示、基于图的推理和答案生成等模块。这些模块在处理复杂KBQA时会遇到不同的挑战。首先,检索源模块从知识库中提取一个与问题相关的图,其中包括相关事实和大量的噪声事实。由于源知识库的不可忽视的不完整性,正确的推理路径可能在提取的图中不存在。在复杂问题的情况下,这两个问题更容易出现。其次,问题表示模块理解问题并生成指导推理过程的指令。当问题变得复杂时,这一步变得具有挑战性。然后,通过语义匹配在图上进行推理。在处理复杂问题时,这些方法通过语义相似性来对答案进行排名,而不在图中进行可追踪的推理,这阻碍了推理分析和故障诊断。
3.1 不完整的知识库
3.1.1 补充知识库
一般而言,基于信息检索的方法通过在图结构上进行推理来找到答案。这个图结构通常是从知识库中提取的一个与问题相关的图。然而,由于知识库的不完整性和启发式图生成策略带来的噪声图上下文,这些问题特定的图永远不会是完美的。
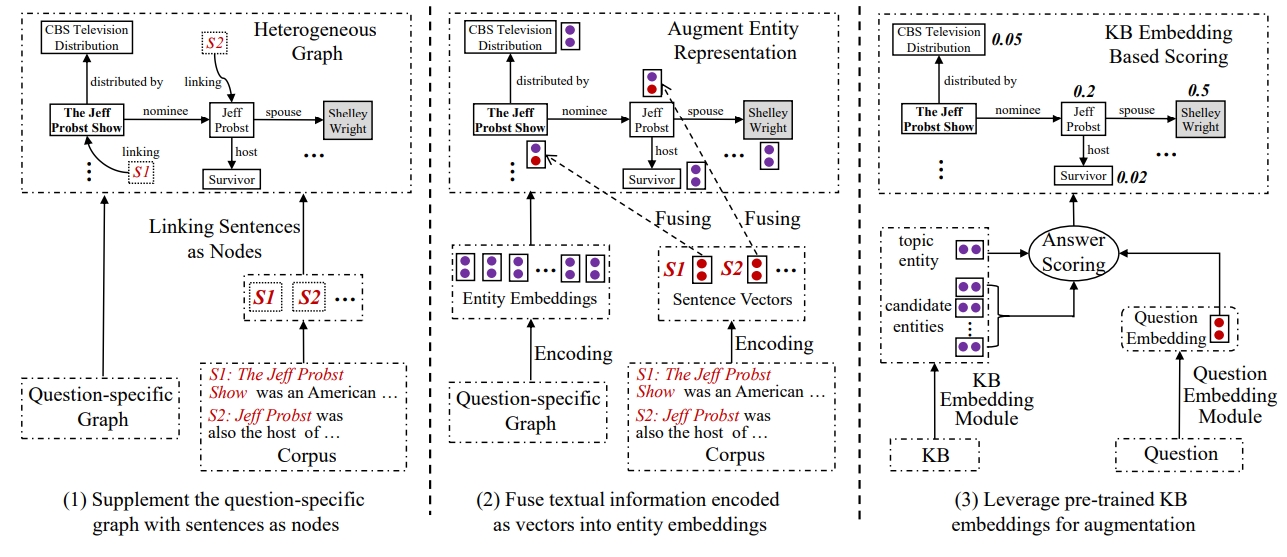
用句子作为节点来补充不完整的知识库、通过文本信息增强实体表示、用预训练的知识库嵌入来补充不完整的图
3.1.2 处理嘈杂的图上下文
由于问题特定图通常是使用启发式方法构建的,它可能引入冗余甚至与问题无关的嘈杂图上下文(包括实体和句子节点)。与只需要1跳推理的简单问题相比,为复杂问题构建的问题特定图更有可能包含嘈杂的图上下文。在这样的嘈杂图上进行推理对于复杂问题构成了巨大的挑战,同时也降低了模型训练的效率。
构建精确的问题特定图。一个直观的想法是构建一个相对小而精确的图以进行后续推理。为了实现这个目标,Sun等人提出了在主题实体和答案实体之间的最短路径监督下,通过迭代检索和推理过程构建异构图。在最近的研究中,Zhang等人提出了一个可训练的子图检索器(SR),用于检索相关的关系路径以进行后续推理。他们的实验结果证明,这样的精确图可以为基于信息检索的方法带来显著的性能提升。
在推理过程中过滤掉无关信息。除了为后续推理构建小而精确的图外,一些研究工作还提出在推理过程中过滤掉无关信息。注意力机制,对于消除无关特征非常有效,已被现有的基于信息检索的方法采用,以在推理过程中保留相关信息。类似地,Yasunaga等人采用了每个节点的预训练语言模型评分,条件是问题回答上下文作为相关性分数,以引导后续推理过程。
3.2 理解复杂语义
理解复杂问题是后续推理的前提。然而,复杂问题包含复合语义,并需要特定的知识(例如命名实体、序数推理)来回答。由于复杂问题具有这种固有属性,专为简单问题理解设计的方法可能不适用于复杂问题。
3.2.1 理解复合语义
基于信息检索的方法通常通过神经网络(例如,LSTM和GRU)直接将问题编码为低维向量来生成初始问题表示q。通过上述方法获得的静态推理指令(例如,q的最终隐藏状态)无法有效表示复杂问题的复合语义,这对于指导问题特定图上的推理构成了挑战。为了全面理解问题,一些研究在推理过程中动态更新推理指令。
3.2.2 知识表示
除了组合语义之外,复杂问题可能还包含知识密集型的标记或短语(例如命名实体、序数约束),这会阻碍基于文本的语义理解。除了问题文本之外,外部知识被作为输入来帮助理解这些复杂问题。
3.3 无法解释的推理
由于复杂问题通常按顺序查询多个事实,系统应该能够基于可追溯的推理过程在图上准确预测答案。尽管神经网络非常强大,但推理模块的黑盒风格使得推理过程难以解释,也难以引入用户交互以进一步改进。为了获得更可解释的推理过程,推理是通过多步中间预测来执行的。在推理过程中,KBQA模型生成一系列推理状态,尽管最终状态用于生成答案预测,但中间状态可能有助于生成中间预测(即匹配的关系或实体),以提高可解释性。更重要的是,中间预测使得通过用户交互更容易检测到虚假或错误的推理。