学习稀疏检索的统一框架
学习稀疏检索的统一框架
学习稀疏检索是一种结合机器学习和信息检索的方法,旨在优化文本检索效果。通过学习模型,将查询和文档映射到稀疏表示空间,实现高效的检索。在训练阶段,利用已标记的查询-文档对和相关性标签,通过优化模型参数,学习如何选择、加权和组合特征,使相关文档在稀疏表示中更接近查询。学习稀疏检索方法可应用于大规模信息检索任务,如搜索引擎和推荐系统,以提高检索效率和准确性。
1 背景和目的
自然语言查询的文本检索是信息检索(IR)系统的核心任务。之前的研究采用了两阶段的流程来解决这个问题,首先通过快速的检索器从文档集合中检索出一组初始文档,然后由更复杂的模型进一步重新排名。对于第一阶段的检索,神经网络的密集表示在语义匹配方面具有很大的潜力,在许多自然语言处理任务中超越了稀疏方法,但在强调长文档检索和精确匹配的情况下不一定成立。此外,对于极大规模(例如100亿)的候选文档集合,密集方法不得不在效率与准确性之间权衡。传统的基于术语的稀疏表示,也称为词袋(BoW),如TF-IDF和BM25,可以有效地进行字面匹配,因此在工业级IR系统中扮演着核心角色。然而,传统的基于术语的方法通常被认为表示能力不足,不适用于语义级匹配。
学习稀疏检索最早由Zamani等人在论文《From Neural Re-Ranking to Neural Ranking: Learning a Sparse Representation for Inverted Indexing》中提出。SNRM(Standalone Neural Ranking Model)是一种独立的神经排序模型,旨在解决神经排序模型在效率方面的问题。它通过引入稀疏属性,为每个查询和文档学习潜在的稀疏表示。其中“潜在”Token在反向索引过程中扮演传统术语的角色。关于SNRM的一个挑战是它失去了原始术语的可解释性,这对于工业系统至关重要。
该论文研究了学习稀疏检索(LSR)方法,这是一类用于生成查询和文档稀疏词汇表示的首阶段检索方法,用于倒排索引。虽然有许多LSR方法已被引入,其中Splade模型在MSMarco数据集上取得了最先进的性能,但不同的实验设置和配置难以进行有效的比较和洞察。在这项工作中,作者分析了现有的LSR方法,识别出关键组成部分,并建立了一个统一的LSR框架,将所有LSR方法放置在一个统一的视角下。然后,作者重新实现了所有重要的方法,并在相同环境中重新训练,以便量化不同框架组成部分如何影响效果和效率。研究发现:(1)文档词项加权对方法的效果最具影响,(2)查询加权略有正面影响,(3)文档扩展和查询扩展效果相互抵消。因此,作者提出了如何从最先进的模型中移除查询扩展,以显著降低延迟,同时在MSMarco和TripClick数据集上保持性能。该工作旨在提供一种统一的LSR框架,深入分析了不同组成部分对效果和效率的影响,并为LSR方法的进一步优化提供了指导。
2 统一框架的建立
学习稀疏检索 (LSR) 使用查询编码器 和文档编码器 将查询和文档投影到词汇大小的稀疏向量: 和。 查询与文档之间的分数是其对应向量之间的点积:。 该公式与 BM25 等传统稀疏检索方法密切相关; 事实上,BM25 可以表述为:
使用 BM25,IDF 和 TF 分量可以被视为查询/文档术语权重。 LSR 的不同之处在于使用神经模型(通常是 Transformer)来预测术语权重。 LSR 与稀疏检索的许多技术兼容,例如倒排索引和附带的查询处理算法。 然而,LSR 权重的差异可能意味着现有的查询处理优化变得不太有用,从而激发新的优化。
在本节中,我们介绍一个由三个组件(稀疏编码器、稀疏正则化器、监督)组成的概念框架,它捕获了我们观察到的现有学习稀疏检索方法之间的关键差异。 随后,我们描述了文献中的 LSR 方法如何适应这个框架。
稀疏(词法)编码器是学习稀疏检索方法的主要组成部分,用于将查询和段落编码为相同维度的权重向量。与密集编码器相比,稀疏编码器具有三个主要特征。首先,稀疏编码器生成稀疏向量,其中大多数权重为零,这由稀疏正则化器控制。其次,稀疏权重向量的维度通常与词汇表中的术语数量相对应,而密集编码器生成较小的压缩向量,没有明确的术语与维度对应关系。第三,稀疏编码器只产生非负权重,因为稀疏检索方法依赖于传统词汇搜索的堆栈,其中权重始终是非负的术语频率。
这些差异可能导致学习稀疏检索(LSR)方法和密集检索方法在行为上有系统性的不同。一些研究表明,LSR模型和一些密集模型在基准测试上表现更好,例如在BEIR基准上,LSR模型和类似ColBERT的令牌级密集模型通常具有更好的泛化能力。近期也有工作提出了混合检索系统,将稀疏表示和密集表示相结合,以获得域内和域外的有效性优势。
1.稀疏编码器: 稀疏编码器是对查询和段落进行编码的组件,构建在Transformer主干上。不同的稀疏编码器架构包括:
a.BINARY: 标记输入中的术语,并考虑术语的存在。
b.MLP: 使用多层感知器生成每个输入项的分数,重点关注术语权重。
c.expMLP: 在MLP编码器之前进行术语扩展。
d.MLM: 根据BERT的屏蔽语言模型生成术语权重。
e.clsMLM: 简化版的MLM编码器,仅输出序列中位置0的[CLS]标记的logits。
2.稀疏正则化器: 控制权重向量的稀疏性,以提高查询处理效率。包括:
a.FLOPs: 估计点积运算的浮点运算次数,通过平滑函数计算权重向量之间的点积。
b.Lp 范数: 应用于输出向量的规范化,减轻过度拟合。
c.Top-K: 保留top-k最高的权重,将其余置零。
3.监督: 为了区分LSR方法并考虑效果,引入监督组件,包括负样本和标签。
a.负样本: 用于训练的负样本影响性能,可以从语料库中选择难度适中的负样本。
b.标签: 标签分为类型(人工、教师、自我)和级别(术语级、段落级)。 大多数方法使用段落级标签。
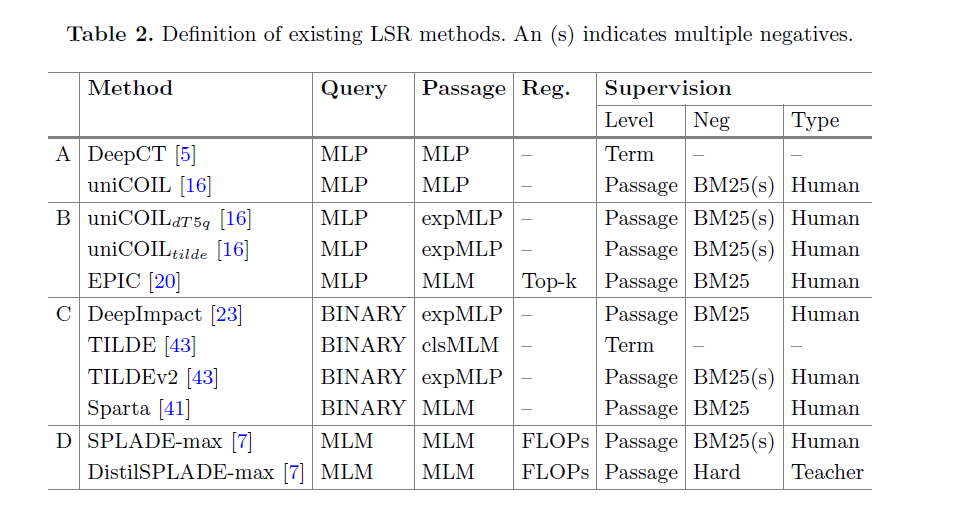
在表中,总结了适合概念框架的学习稀疏检索(LSR)方法。这些方法可以根据概念相似性分为四个组:
A. 无扩展方法: 包括 DeepCT 和 uniCOIL。它们使用MLP编码器对查询和文档中的术语进行加权,Equ2稍作修改。 DeepCT在监督方面使用术语召回进行监督,而uniCOIL使用段落级别标签。
B. 无查询扩展方法: 包括 uniCOIL 、uniCOIL 和EPIC。它们使用具有文档扩展功能的expMLP或MLM编码器替代A组中的MLP文档编码器。其中,uniCOIL 和uniCOIL 使用第三方模型进行术语扩展,而EPIC使用训练有素的MLM架构进行端到端的文档扩展和术语评分。
C. 无查询扩展或加权方法: 包括DeepImpact、Sparta、TILDE和TILDEv2。它们简化了B组中的方法,通过删除查询编码器来减少查询编码时间,没有查询扩展和加权功能。
D. 充分展开和加权方法: 包括Splade-max和distilSplade-max。它们使用共享的MLM架构在查询和文档端进行加权和扩展。这些方法没有选择前k个项,而是使用FLOPs正则化器来稀疏表示。Splade-max和distilSplade-max之间的差异在于监督方法,其中Splade-max使用多个批次的BM25负样本进行训练,而distilSplade-max使用蒸馏技术和硬负样本进行训练。
总的来说,这些LSR方法在概念框架下的适用性根据是否进行扩展、加权以及监督方法的不同而有所不同。不同方法之间微小的差异可能涉及非线性选择、术语质量或段落质量函数等方面。
3 实验
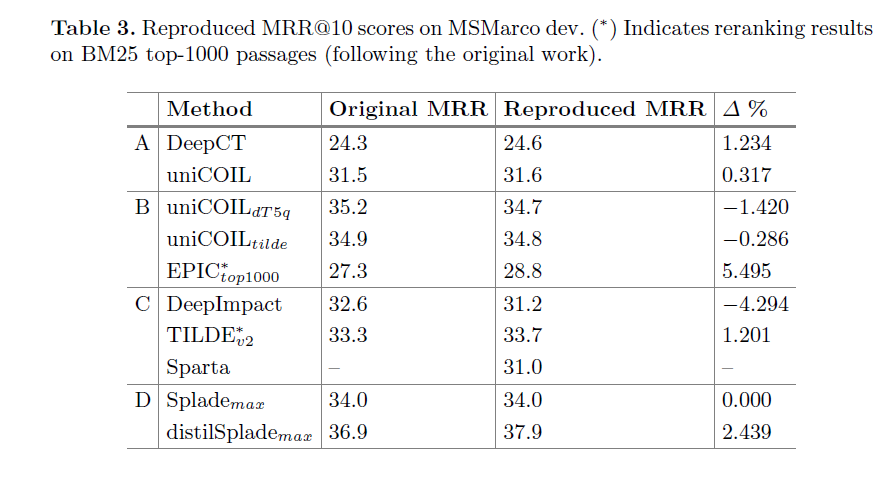
作者对已有的LSR方法进行复现,以下是复现结果,效果采用MRR指标进行评估。
4 结论
4.1 研究问题一(RQ1):LSR论文的结果是否可重现?
在复现过程中,我们采用了原始论文和代码中所述的实验设置来训练LSR方法,并将结果与原始工作进行比较。大部分方法的得分要么略高于原始工作,要么与其相当。其中,DeepCT、uniCOIL、EPIC、TILDE 和 distilSplade 的MRR稍高,而DeepImpact 和 uniCOIL 的复现得分稍低。Sparta方法在原始论文中没有进行MSMarco评估,因此无法与其他方法进行比较。
复现的结果显示,DeepCT 和 uniCOIL(没有 docT5query 扩展)方法通常效率较低,而 distilSplade 方法实现了最高的 MRR。值得注意的是,具有相同架构但不同训练方法的方法之间得分差异显著。例如,将 DeepCT 的监督信号从令牌级权重改为段落级相关性,使得 uniCOIL 方法的 MRR 从 24.6 跃升 28% 至 31.6。这表明监督对性能至关重要,段落级别标签有助于更好地学习术语权重以实现段落级相关性。同样,使用硬负样本挖掘和蒸馏技术将 Splade 模型的 MRR 从 34.0 提高到 37.9。这种监督方法的改变使得 distilSplade 成为考虑中最有效的 LSR 方法。如果没有这种高级训练,Splade 的性能与 uniCOIL 和 uniCOIL 相当。在组 (B) 中,EPIC 方法似乎已经达到其性能极限,其 MRR 显著低于两个 uniCOIL 变体。这可能是因为 EPIC 最初是在 40000 个三元组上进行训练的,而其他方法是在多达数百万个样本上进行训练的。
4.2 研究问题二(RQ2):LSR方法如何在最新的高级训练技术下表现?
Splade模型在MSMarco上展现出令人印象深刻的排名得分。尽管这些改进可能是因为架构选择(如查询扩展)等原因,但Splade还通过高级训练过程中挖掘的难负样本和交叉编码器蒸馏等技术受益。实验结果显示,与Splade相同的训练方式使得许多旧方法的效果显著提升。其中,旧的EPIC模型的MRR@10分数增加了36%,变得与Splade相当。
由于不同环境可能引起公平比较的困难,作者在一致的环境中进行了所有方法的训练,证明这是有效的。在最有效的监督设置下,即使用蒸馏和硬负片进行训练的 distilSplade ,作者发现最低效的方法(如DeepCT)和最高效的方法(如distilSplade )保持在相同位置。而介于这两个端点之间的方法根据其效果而变化。实验结果显示,多数方法在这种设置下取得了提升,其中EPIC和Sparta的改进最为显著,分别相对于MSMarco提升了8.0和4.2个MRR点。EPIC在训练时间更长和改进的监督下,有效性提升使其在相对排名中跃升为第二位,并与MSMarco上的distilSplade 相竞争。而在TREC DL 2019和TREC DL 2020上,EPIC和distilSplade 之间的NDCG@10差距更大。
作者还注意到在使用不同架构类型方面,使用MLM架构(无论是在文档端还是查询端)的方法通常在三个数据集上表现更好,然而MLM也会导致显著增加索引大小和延迟。最后,通过引入独立的编码器以减少文档和查询之间的术语激活概率相似性,成功解决了Splade中的延迟问题,进一步支持了这一解决方法的重要性。
4.3 研究问题三(RQ3):编码器架构和正则化的选择如何影响结果?
通过在共同训练环境中进行实验,作者量化了不同架构决策(如扩展、加权和正则化)对系统效果和效率的影响。他们发现文档加权对系统的有效性影响最大,而查询加权的影响较为适中,尽管查询加权通过减少无用术语改善了检索延迟。查询和文档扩展之间存在抵消效应,因为一侧扩展时,另一侧的扩展对系统效果的提升会受到影响,表明查询扩展对于LSR系统表现良好并不是必需的。
作者的实验结果还表明,不同的正则化方法对有效性和效率影响不大。总体而言,这些发现揭示了在优化LSR方法时,文档加权、查询加权、查询扩展和文档扩展之间的权衡,同时对正则化方法的选择在某些情况下可能不太重要。
作者展示了仅在查询端或文档端进行扩展的系统结果。这些结果进一步支持了之前的发现,即查询扩展和文档扩展之间存在抵消效应。他们还指出,将MLM查询编码器替换为MLP查询编码器(distilSplade )可以在不显著影响排名指标的情况下降低检索延迟,从而提高效率。这种变化可以被视为更有效的替代方式,进一步强调了提高LSR方法效率的可能性。