Self-RAG:通过自我反思学习检索、生成和批判
Self-RAG:通过自我反思学习检索、生成和批判
本文介绍了一篇关于RAG的论文,该文提出了一种称为自我反思检索增强生成(Self-RAG)的框架,其通过检索和自我反思来提高LM的质量和真实性。
提示
论文名称:Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
1 介绍
尽管大型语言模型(LLM)具有非凡的能力,但由于其仅依赖于所封装的参数知识,因此它们通常会产生包含事实不准确的响应。检索增强生成(RAG)是一种通过检索相关知识来增强LMs的特别方法,减少了此类问题。然而,不分青红皂白地检索和合并固定数量的检索段落,无论检索是否必要,或段落是否相关,都会削弱LM的多功能性,或可能导致无益的响应生成。
为了进一步改进,作者提出了自反思检索增强生成(Self-RAG, Self-Reflective Retrieval-Augmented Generation)。这是一个新框架,它不仅可以根据需要自适应地检索段落(即:模型可以判断是否有必要进行检索增强),还引入了名为反思令牌(reflection tokens)的特殊令牌,使LM在推理阶段可控。
2 模型概述
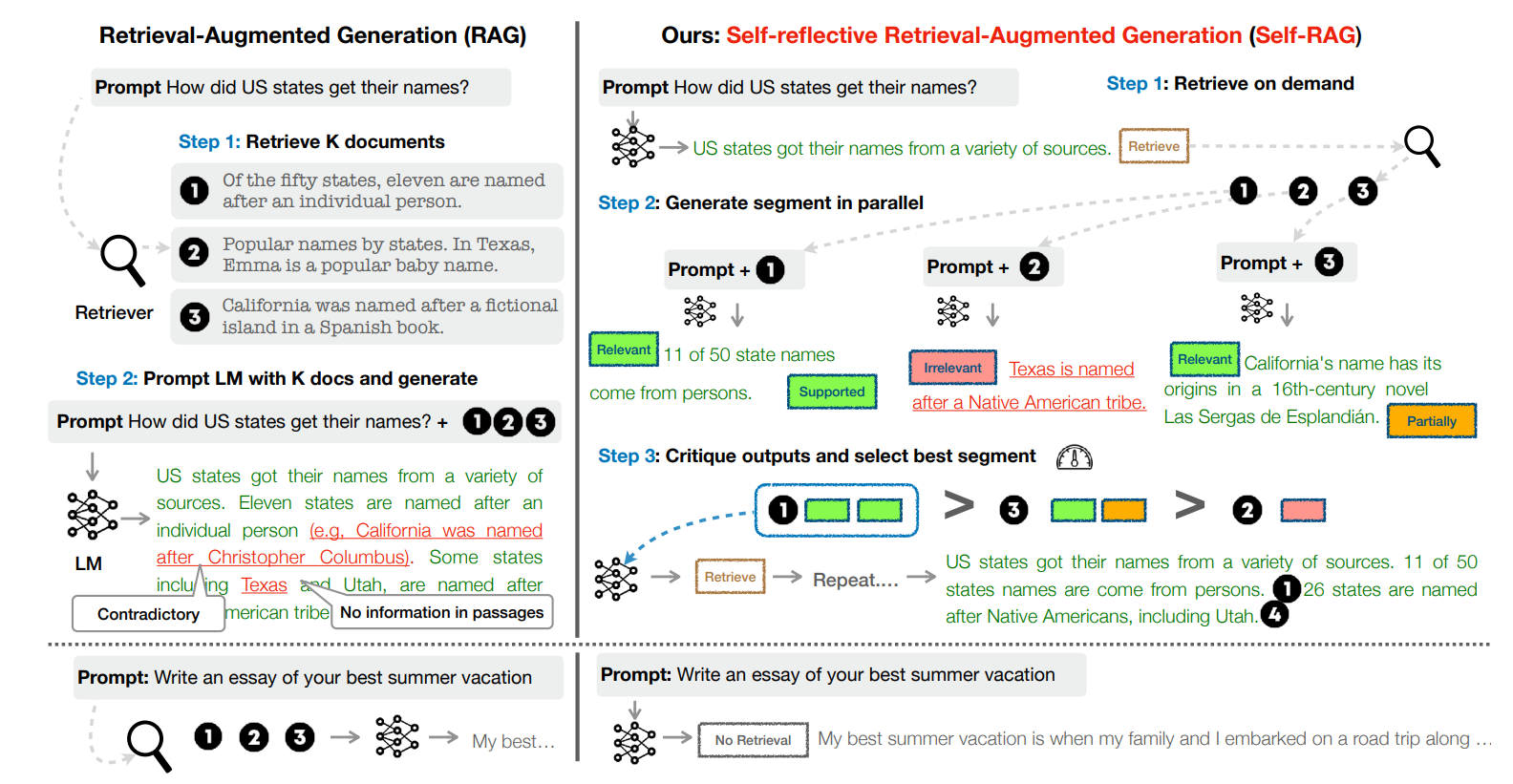
如上图2.1,Self-RAG的实现主要分为三个步骤:按需检索、并行生成以及评价与选择。
按需检索:首先,Self-RAG 依据检索令牌(retrieval token)以评估是否需要检索,并控制检索组件。如果需要检索,LM将调用外部检索模块查找相关文档。
并行生成:如果不需要检索,模型会预测下一个输出段,就像在标准 LM 中一样。如果需要检索,模型首先生成一个评论令牌[IsREL]来评估检索到的文档与问题是否相关,然后利用与问题相关的段落来生成后续内容。
评价与选择:对于通过检索段落生成的内容,模型将生成另一个评论令牌[IsSUP],用于评估生成内容收到检索段落的支持度。随后,综合所有评论令牌,选择优秀的生成内容作为本次片段的输出并继续处理下一片段。
在所有片段生成完毕后,生成评论令牌[IsUSE],用于评估整体内容对问题解答的有效性。
2.1 反思令牌
Self-RAG 中包含有四种反思令牌,如下图2.2所示。

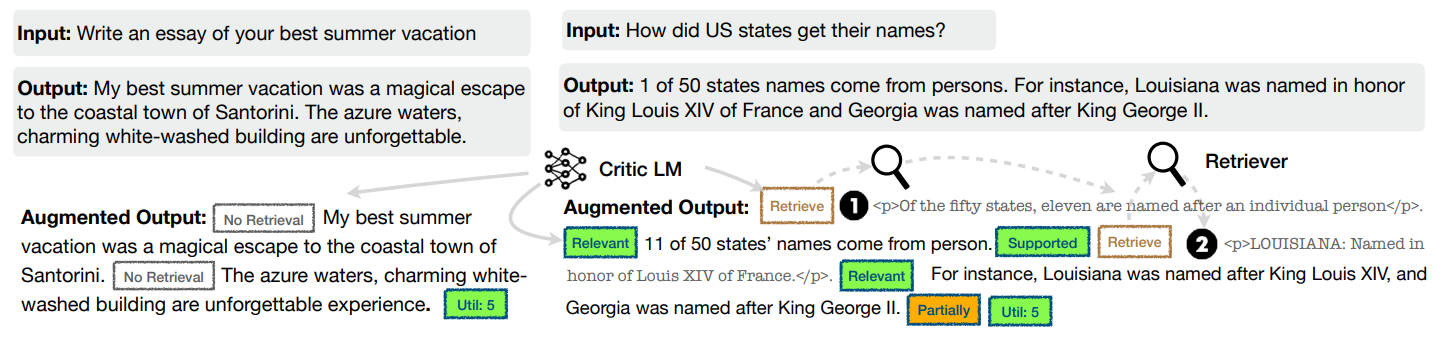
其中,[Retrieve]用于评估是否需要检索文档,[IsREL]用于评估检索到的段落是否与问题相关,[IsSUP]用于评估生成内容受到检索段落的支持度(完全支持、部分支持或不支持),[IsUSE]用于评估整体生成内容对问题的有效性。
2.2 推理算法
Self-RAG 的推理使用到了三个组件:检索器(Retrieve)、生成器(Generate)以及评论器(Critique),其具体推理算法如下图2.3所示。

值得注意的是,训练的最终大模型M整合了生成器和评论器的功能,而不再需要分离式的两个模型。
3 训练细节
Self-RAG首先训练一个评论器模型C来生成反思令牌,用于评估检索到的段落和给定任务输出的质量。
随后使用评论器模型C,将反思令牌插入到原离线任务输出中来更新训练语料库。
最后,使用传统的 LM 目标训练最终的生成器模型M,以使 M 能够自行生成反思令牌,而无需在推理时依赖评论器模型C。
3.1 评论模型C的训练
考虑到直接使用如GPT-4的成熟模型,生成反思令牌并更新所有语料库的耗费太大,作者通过提示 GPT-4 生成反思令牌来创建监督数据,然后将其知识提炼到评论模型 C 中。
作者首先选取部分优质输入数据,并做反思令牌的标注演示;随后使用GPT-4生成了每种类型的 4k-20k 个监督训练数据,并将它们组合起来形成 C 的训练数据。手动评估表明,GPT-4 反思令牌预测与人类评估高度一致。
作者使用与生成器 LM 相同的模型(即 Llama 2-7B;Touvron et al. 2023)进行 C 初始化,经训练后评论模型C对大多数反射标记类别的基于 GPT-4 的预测达到了 90% 以上的一致性。
3.2 最终生成模型M的训练
首先由评论模型生成原始输入的反思令牌,随后将原始输入和增加了反思令牌的原始输出一起作为生成模型的训练数据。
与C(评判模型)训练不同,最终生成模型M既要学习预测目标输出又要学习预测反思令牌。
训练期间,将把检索到的文本块(由<p>和</p>围绕)进行遮挡以进行损失计算。这意味着模型在计算损失时不考虑这些检索到的文本块。
原始词汇V通过一组反思tokens(如<Critique>和<Retrieve>)进行扩展。这表示这些tokens被加入到词汇中,使模型能够使用这些特定的tokens来生成输出。
4 Self-RAG与普通RAG优势对比
- 自适应段落检索:通过这种方式,LLM可以继续检索上下文,直到找到所有相关的上下文(当然是在上下文窗口内);
- 更相关的检索:很多时候,embedding模型并不擅长检索相关上下文。Self-RAG可能通过relevant/irrelevant的特殊token来解决这一问题。