RAG增强技术研究综述
RAG增强技术研究综述
本文介绍了大型语言模型中的RAG(检索增强生成,Retrieval-Augmented Generation)技术,深入探讨了RAG的三大组成部分:检索、生成和增强,以及RAG的不同范式。
提示
论文名称:Retrieval-Augmented Generation for Large Language Models: A Survey
论文地址:https://arxiv.org/pdf/2312.10997.pdf
研究作者/机构:同济大学,复旦大学
RAG中的增强围绕三个关键方面展开:增强阶段、增强数据来源和增强过程
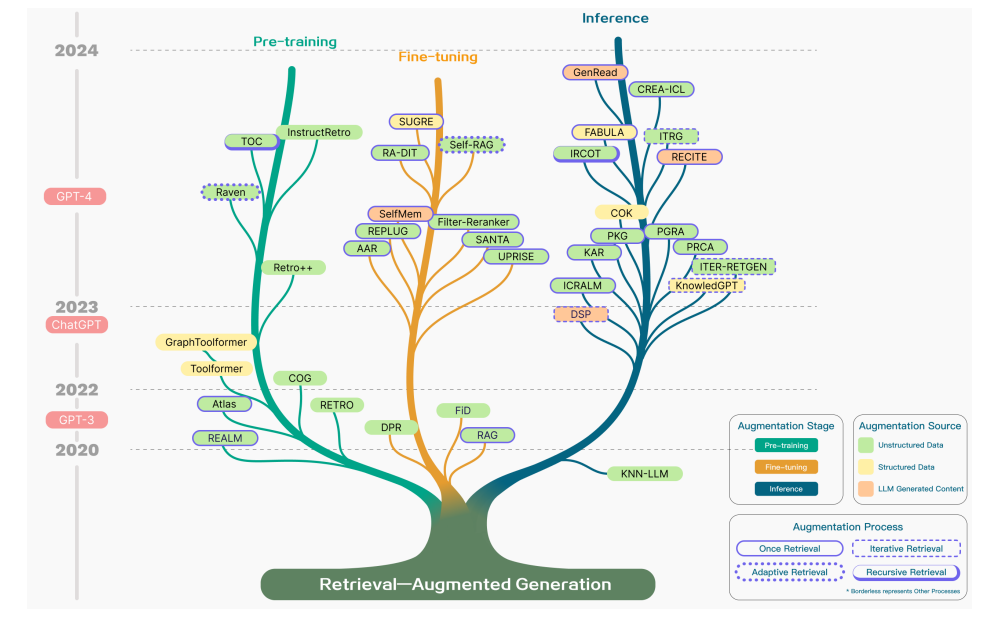
1. RAG增强阶段
1.1 预训练阶段
在预训练阶段,研究人员探讨了通过基于检索的策略来加强PTM(预训练模型,Pre-Training Model)以进行开放领域问答的方法。
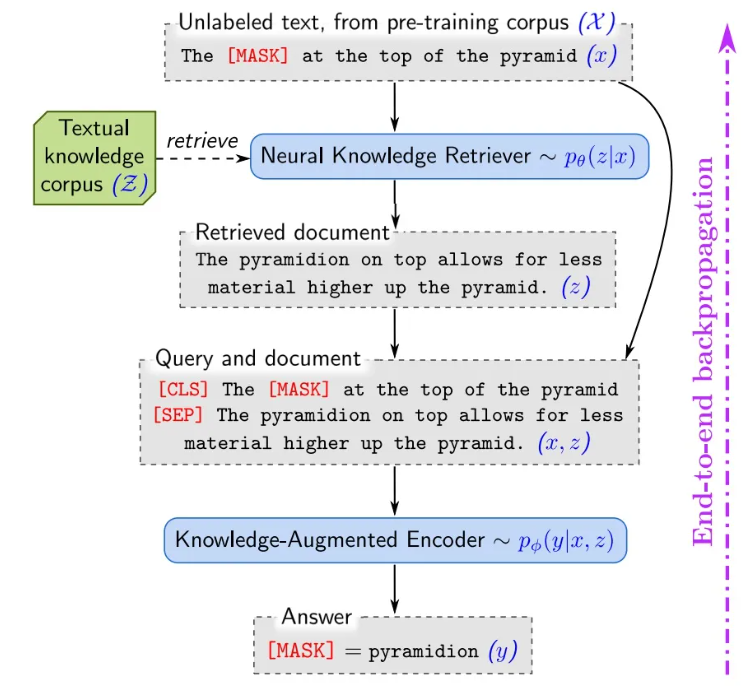
REALM模型采用了结构化、可解释的知识嵌入方法,将预训练和微调构架为MLM(遮蔽语言模型,Masking Language Model)框架内的“Retrieve-Then-Predict”工作流。
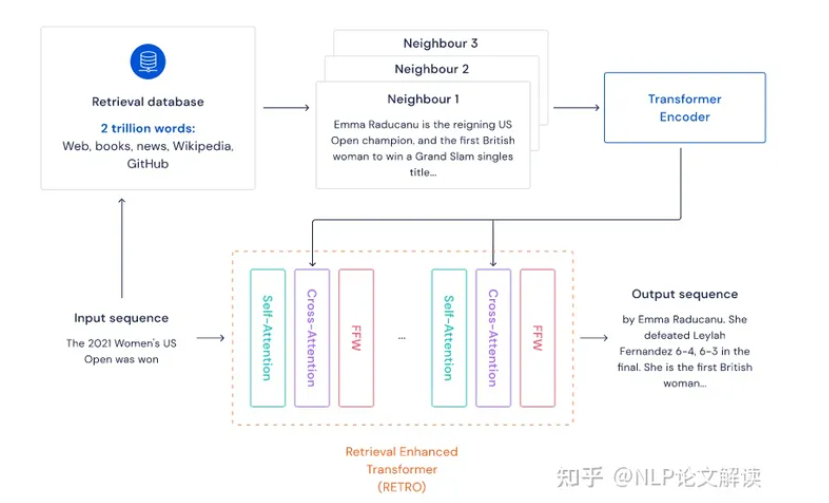
RETRO利用检索增强技术进行大规模从零开始的预训练,实现了在模型参数上的减少,同时在困惑度方面超越了标准GPT模型。RETRO的独特之处在于在GPT模型的基础结构之上增加了一个额外的编码器,用于处理从外部知识库检索到的实体特征。
Atlas也将检索机制纳入T5架构的预训练和微调阶段。它使用预训练的T5来初始化“Encoder-Decoder”语言模型,并使用预训练的Contriever作为密集检索器,提高了复杂语言建模任务的效率。
此外,COG引入了一种全新的文本生成方法,模仿从现有集合中复制文本片段。COG利用高效的向量搜索工具,计算并索引文本片段的上下文意义表示,与RETRO相比,在诸如问答和领域适应等领域展现了卓越的性能。
模型参数的增长规律推动了自回归模型成为主流。研究人员正在将RAG方法扩展到预训练的更大模型上,RETRO++就是这一趋势的典型例子,通过扩大模型参数,同时保持或提高性能。
实证证据强调在文本生成质量、事实准确性、减少有害内容和下游任务能力方面的显著改进,特别是在像开放领域问答这样的知识密集型应用中。这些结果暗示将检索机制整合到自回归语言模型的预训练中是一条有前景的途径,将复杂的检索技术与广泛的语言模型结合起来,产生更精确和高效的语言生成。
增强预训练的好处包括一个强大的基础模型,在使用更少的参数的前提下,在困惑度、文本生成质量和特定任务性能方面超越标准GPT模型。这种方法特别擅长处理知识密集型任务,并通过在专业语料库上训练,促进特定领域模型的发展。
1.2 微调阶段
微调检索器的主要目标是提高语义表示的质量,通过直接使用语料库微调嵌入模型来实现。通过反馈信号将检索器的能力与LLM的偏好对齐,两者可以更好地协调。针对特定下游任务微调检索器可以提高适应性。任务不可知微调的引入旨在提高检索器在多任务场景中的通用性。
通过对检索器和生成器进行协同微调,我们可以提高模型的泛化能力,避免分别训练可能导致的过拟合。然而,联合微调也导致了资源消耗的增加。RA-DIT提出了一个轻量级的双指令调整框架,可以有效地为任何LLM增加检索能力。检索增强的指令性微调更新了LLM,指导它更有效地使用检索到的信息并忽略分散注意力的内容。
尽管微调有其优势,但也存在限制,包括需要专门的RAG微调数据集和大量计算资源的需求。然而,这一阶段允许根据特定需求和数据格式定制模型,与预训练阶段相比可能减少资源使用,同时仍能微调模型的输出风格。
1.3 推理阶段
为了克服初级RAG的限制,高级RAG在推理中引入了更丰富的上下文。
DSP框架利用冻结LM和RM(检索模型,Retrieval Model)之间自然语言文本的复杂交换,丰富了上下文,从而提高了生成结果的质量。
PKG方法为LLM配备了知识引导模块,允许在不修改LM参数的情况下检索相关信息,结合本地模型和LLM模型,本地模型基于开源的自然语言模型(Llama),它可以存储离线的领域知识,将领域知识转化成参数输出,作为background和问题一起传入大模型,实现更复杂的任务执行。
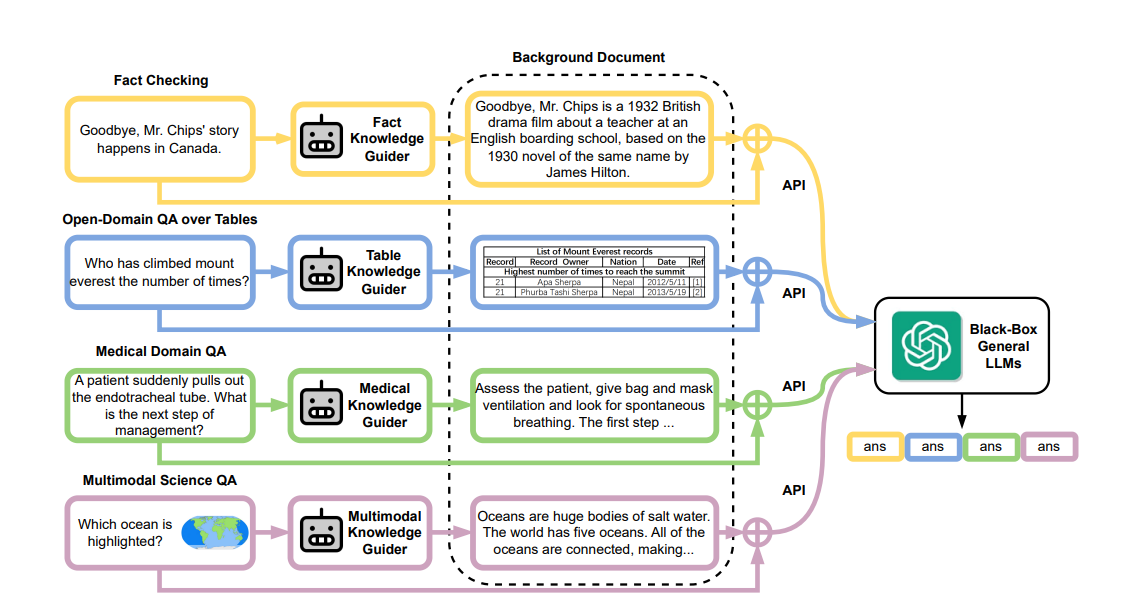
CREAICL采用同步检索跨语言知识来增强上下文,而RECITE是语言模型是prompting的一个新版本,通过提示模板使模型在生成答案之前从记忆中找到其训练语料库中的相关段落,再生成上下文。
在推理阶段进一步精炼RAG过程的方法包括针对需要多步推理的任务。
ITRG以迭代的方式检索信息来确定正确的推理路径,从而提高了任务适应性。ITER-RETGEN采用迭代策略,将原始查询与生成的伪文档合并形成新的查询,将“检索增强型生成(Retrieval-Enhanced Generation)”和“生成增强型检索(Generation-Enhanced Retrieval)”在循环过程中交替进行。
2. RAG增强源
RAG模型的有效性在很大程度上受到增强数据源(Augmentation Source)选择的影响。不同层次的知识和维度需要不同的处理技术。它们被归类为非结构化数据、结构化数据和由LLM生成的内容。最初,增强主要通过非结构化数据实现,如纯文本。这种方法后来扩展到使用结构化数据(例如知识图谱)以进一步改进。最近,研究趋势是利用LLM自身生成的内容进行检索和增强。
2.1 非结构化数据增强
非结构化文本来自语料库,包括用于大型模型微调的提示数据和跨语言数据。检索单元从标记(例如,kNN-LM)到短语(例如COG)以及文档段落,更细的粒度提供了精确性,但增加了检索复杂性。
2.2 结构化数据增强
结构化数据,如KG(知识图谱,Knowledge Graph),提供了高质量的上下文,并减轻了模型幻觉。
RET-LLM从过去的对话中构建知识图谱记忆,用于未来参考。
SUGRE使用图神经网络(GNN)对相关KG子图进行编码,通过多模态对比学习确保检索到的事实和生成的文本之间的一致性。 KnowledGPT生成KB搜索查询,并将知识存储在个性化基础上,增强了RAG模型的知识丰富性和上下文性。
2.3 在RAG中使用LLM生成的内容
针对RAG中外部辅助信息的局限性,一些研究专注于利用LLM的内部知识。
SKR将问题分类为已知或未知,选择性地应用检索增强。
GenRead用LLM生成器替换检索器,发现通过更好地与因果语言建模的预训练目标对齐,LLM生成的上下文通常能够包含更准确的答案。

Selfmem以迭代的方式使用检索增强型生成器创建一个无界的记忆池,使用记忆选择器来选择作为原始问题的双重问题的输出,从而实现生成模型的自我增强。
3. RAG增强过程
近期的研究提出了改进检索过程的方法:迭代检索(Iterative Retrieval)、递归检索(Recursive Retrieval)和自适应检索(Adaptive Retrieval)。 迭代检索允许模型进行多次检索,增强获得信息的深度和相关性。递归检索过程是指一次检索的结果被用作后续检索的输入,有助于深入挖掘相关信息,特别是在处理复杂或多步查询的时候。递归检索通常用于需要逐步方法以收敛于最终答案的场景,如学术研究、法律案例分析或某些类型的数据挖掘任务。另一方面,自适应检索提供了一种动态调整机制,根据不同任务和上下文的特定需求定制检索过程。
3.1 迭代检索
RAG模型中的迭代检索是一个基于初始查询以及截至目前生成的文本反复收集文档的过程,为LLM提供更全面的知识库。这种方法已被证明可以通过多次检索迭代提供额外的上下文参考,增强后续答案生成的健壮性。
3.2 递归检索
递归检索通常用于信息检索和自然语言处理,以提高搜索结果的深度和相关性。
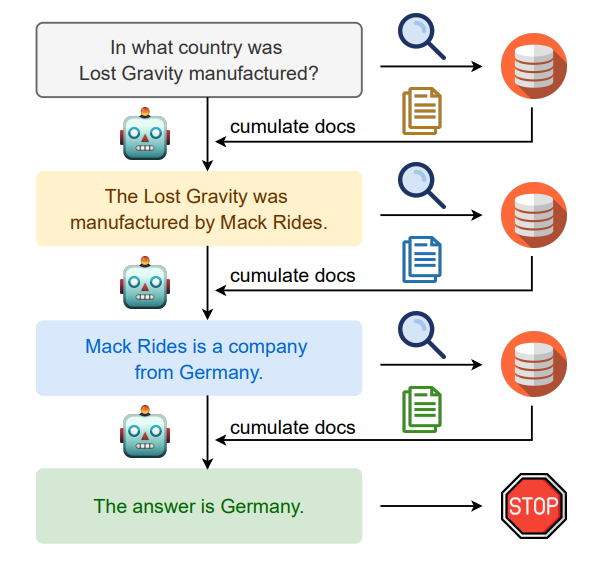
为了能够适应特定数据场景,可以采用递归检索和多跳(Multi-Hop)检索技术。递归检索涉及使用结构化索引以分层方式处理和检索数据,这可能包括在基于这一摘要进行检索之前对文档或冗长的PDF文件的部分内容进行摘要。随后,在文档内的二次检索细化了搜索,体现了这一过程的递归性质。相比之下,多跳检索旨在更深入地挖掘图结构化数据源,提取相互关联的信息。
该过程涉及基于前次搜索结果迭代地优化搜索查询。递归检索旨在通过反馈循环逐渐聚焦到最相关的信息上,以增强搜索体验。IRCoT使用思维链来指导检索过程,并利用获得的检索结果优化CoT
3.3 自适应检索
自适应检索方法,例如Flare和SelfRAG所展示的那样,通过使LLM能够主动确定检索的最佳时刻和内容,从而优化RAG框架,提高检索信息的效率和相关性。
这些方法是一个更广泛的趋势的组成部分,其中LLM在其操作中运用主动判断,代表性模型代理包括AutoGPT、Toolformer和Graph-Toolformer。以Graph-Toolformer为例,其将检索过程分为不同步骤,其中LLM会自发地使用检索器,应用Self-Ask技术,并使用少量提示来启动搜索查询。这种主动性允许LLM决定何时搜索必要信息,类似于代理使用工具的方式。
WebGPT集成了一个强化学习框架来训练GPT-3模型,使其在文本生成期间能够自主使用搜索引擎。WebGPT使用特殊标记来指导这个过程,以便执行诸如搜索引擎查询、浏览结果和引用参考资料等操作,从而通过使用外部搜索引擎来扩展GPT-3的能力。