基于检索增强的文本生成调研
基于检索增强的文本生成调研
本文旨在对基于检索增强的文本生成方法进行调研。它首先强调了检索增强生成的泛化范式,然后根据不同的任务回顾了相应的方法,包括对话响应生成、机器翻译和其他生成任务。最后,它指出了一些在最近的方法之上促进未来研究的有前景的方向。
论文名称:A Survey on Retrieval-Augmented Text Generation
1 检索增强生成(RAG)框架
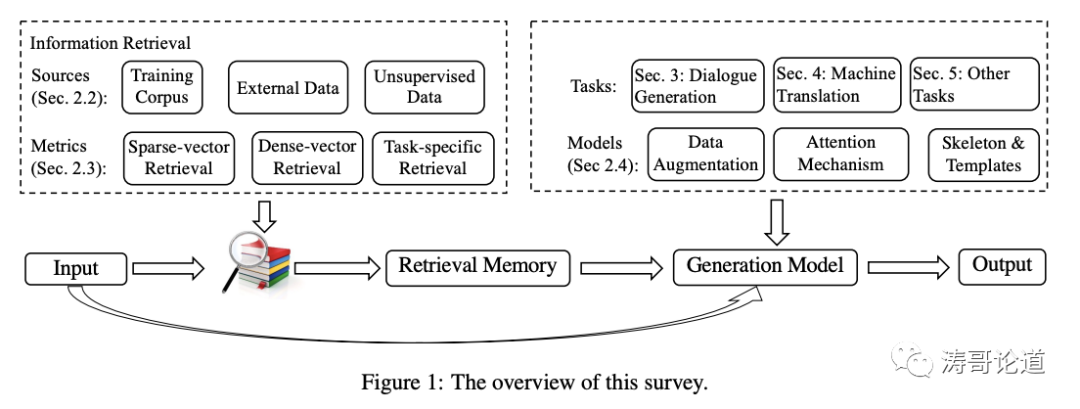
文章中提到了以下几点:
(1)RAG是一种新兴的文本生成范式,将新兴的深度学习技术和传统的检索技术相结合。
(2)RAG框架包括三个关键组件:检索源(训练语料、外部数据、非监督数据)、检索指标(稀疏向量、密集向量、特定任务的检索)和集成方法(数据增强、注意力机制、框架提取)。
(3)RAG通过检索相关的实例来为文本生成提供额外的上下文信息和知识,从而帮助改进文本生成性能。
(4)RAG框架已经在对话响应生成、机器翻译等多个文本生成任务中被验证是有效的。
(5)RAG框架的优势在于可以显式地获取知识,而不是隐式地存储在模型参数中,因此具有很强的可扩展性。
综上所述,RAG框架是最近获得广泛关注的一种新的文本生成范式,其关键思想是利用检索相关记忆来辅助和改进文本生成。
2 主流的检索技术
文章中提到的检索技术主要有以下几种:
(1)稀疏向量检索
例如 TF-IDF 和 BM25 等基于关键词匹配的传统检索方法。依赖倒排索引,可以高效匹配关键词。
(2)密集向量检索
例如基于BERT的编码器将文本映射到低维向量空间,然后计算向量之间的内积作为相似度。优点是可以捕捉语义相似性,而不仅仅是词面相似性。
(3)特定于任务的检索
不仅考虑通用的文本相似性,而是学习一个针对下游任务优化的检索指标,使检索的记忆真正对生成质量有提升。
3 稀疏向量检索技术
BM25是一种常用的稀疏向量文本检索算法,其主要思想和步骤如下:
(1)对检索语料建立倒排索引,记录每个词出现在哪些文本中。
(2)对查询进行分词,获得查询的词袋表示。
(3)计算查询中每个词与语料中每个文本的匹配分值。
其中IDF(q)表示词q的逆文档频率,tf(q,d)表示词q在文本d中出现的次数,|d|表示文本d的长度,avgdl表示所有文本的平均长度。k1,b为调优参数。
(4)对每个文本d的所有匹配分值求和,获得查询与该文本的相似度分数。
(5)根据相似度对文本排序,返回与查询最相似的Top-N文本。
BM25通过考虑词频、逆文档频率等统计信息,能够计算查询和文本之间的相关性。相比简单的词集匹配,它更加强大和准确。BM25至今仍被广泛使用于搜索引擎和信息检索任务中。
4 密集向量检索方法
文章中提到的基于密集向量的检索方法主要包括:
(1)基于BERT的检索
使用BERT等预训练语言模型作为encoder来获得文本的向量表示,然后计算向量相似度。
(2)基于sentence-transformers的检索
使用特定预训练的句子级语义向量,如SBERT、Sentence-BERT等,来表示文本。
(3)基于迁移学习的检索
在目标任务的数据上微调预训练模型,使文本向量更适合下游任务。
(4)对比学习检索
加入负样本,使正样本的文本向量更聚集。
(5)硬匹配检索
直接取向量的内积或余弦相似度作为匹配分值。
(6)软匹配检索
加入一个预测匹配分值的小网络,而不是直接硬匹配。
(7)跨语言检索
训练一个跨语言的文本语义匹配模型。
(8)基于图像的检索
利用图像-文本的预训练模型获得跨模态的语义向量。
(9)基于知识图谱的检索
编码知识图谱关系来增强文本语义。
5 特定任务检索
特定于任务的检索是指检索指标不仅考虑通用的文本相似度,而是针对下游任务学习一个最优的指标。
举例来说,在对话系统中,根据通用相似度检索出的上下文并不一定能产生最相关的回复。为了让检索出的记忆真正提升回复的质量,可以:
(1)构建一个端到端的检索-生成模型。
(2)通过最大化回复质量的目标,来反向传播训练检索模块。
(3)让检索模块学会检索出对回复生成最有帮助的记忆。
相比通用相似度,这种特定于生成任务优化的检索指标可以提升生成性能,因为它直接关联了检索和生成的目标。
类似地,这种思想也可以应用到其他生成任务中,通过使检索指标针对任务目标来获得最佳的记忆检索效果。这是当前研究的一个重要方向。
6 集成方法
文章中提到了几种集成检索记忆的方法:
(1)数据增强
将检索的结果,作为大模型的上下文,让大模型参考上下文进行内容生成。
(2)注意力机制
采用额外的encoder对检索文本编码,并通过注意力机制集成。
(3)框架提取
从检索结果中提取框架信息,避免不相关内容对生成造成负面影响。这种扩展性强,可以深入研究。
总之,核心思路是引导模型明确区分输入和检索记忆,避免过度依赖检索内容而产生错误。同时通过端到端学习,使模型理解如何最有效利用检索信息。
7 未来研究方向
文章最后提出了以下几个未来的研究方向:
(1)提高检索的准确性:现有模型对检索质量很敏感,需要提高处理不太相似检索结果的鲁棒性。
(2)提高检索效率:加大检索池会提高相关性,但降低效率,需要在两者间取得平衡。
(3)本地与全局优化:理论上联合训练检索和生成似乎更优,但在实践中仍存在差距需要研究。
(4)多模态:可以扩展到图像、语音等多模态任务,利用多模态检索增强文本生成。
(5)多样性与可控性:现有检索过于单一,需要探索多样性的检索方式;也可以研究控制检索记忆的方法。
(6)结构化检索:现有检索侧重无结构文本,可以引入结构化知识的检索。
(7)强化学习:检索可以看作是生成的行为选择,可以引入强化学习进行优化。
综上,文章对未来研究提出了很好的建议和指导,给出了可能的新方向,为研究者提供了很好的思路。