ChatGLM2架构升级
ChatGLM2架构升级
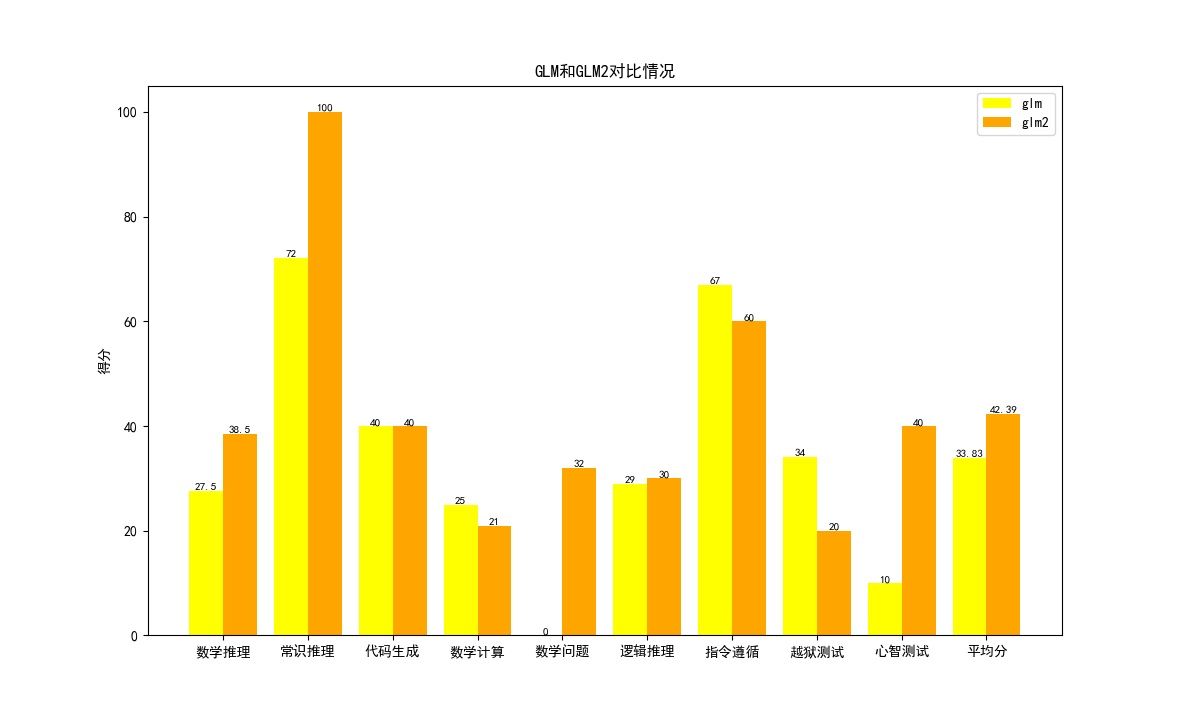
ChatGLM2-6B使用了GLM的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B在MMLU(+23%)、CEval(+33%)、GSM8K(+571%)、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
(1)更强大的性能:基于ChatGLM初代模型的开发经验,官方全面升级了 ChatGLM2-6B 的基座模型。
(2)更长的上下文:基于FlashAttention技术,官方将基座模型的上下文长度(Context Length)由ChatGLM-6B的2K扩展到了32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的ChatGLM2-6B对单轮超长文档的理解能力有限,官方会在后续迭代升级中着重进行优化。
(3)更高效的推理:基于Multi-Query Attention技术,ChatGLM2-6B有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4量化下,6G显存支持的对话长度由1K提升到了8K。
(4)更开放的协议:ChatGLM2-6B权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。如果您发现官方的开源模型对您的业务有用,官方欢迎您对下一代模型ChatGLM3研发的捐赠。
1 基座模型的升级
1.1 Transformer架构
Encoder-Decoder变成Decoder-only。
1.2 词汇表大小
130344减小到64794。
由于抛弃了NLU任务,只保留NLG生成任务,因此不再包含mask token。
1.3 模型结构
1.3.1 总体架构
ChatGLM-6B的总体架构如下所示。
<bound method Module.modules of ChatGLMForConditionalGeneration(
(Transformer): ChatGLMModel(
(word_embeddings): Embedding(150528, 4096)
(layers): ModuleList(
(0-27): 28 x GLMBlock(
(input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(Attention): SelfAttention(
(rotary_emb): RotaryEmbedding()
(query_key_value): QuantizedLinear(in_features=4096, out_features=12288, bias=True)
(dense): QuantizedLinear(in_features=4096, out_features=4096, bias=True)
)
(post_Attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(mlp): GLU(
(dense_h_to_4h): QuantizedLinear(in_features=4096, out_features=16384, bias=True)
(dense_4h_to_h): QuantizedLinear(in_features=16384, out_features=4096, bias=True)
)
)
)
(final_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=4096, out_features=150528, bias=False)
)>
ChatGLM2-6B的总体架构如下所示。
ChatGLMForConditionalGeneration(
(Transformer): ChatGLMModel(
(embedding): Embedding(
(word_embeddings): Embedding(65024, 4096)
)
(rotary_pos_emb): RotaryEmbedding()
(encoder): GLMTransformer(
(layers): ModuleList(
(0-27): 28 x GLMBlock(
(input_layernorm): RMSNorm()
(self_Attention): SelfAttention(
(query_key_value): Linear(in_features=4096, out_features=4608, bias=True)
(core_Attention): CoreAttention(
(Attention_dropout): Dropout(p=0.0, inplace=False)
)
(dense): Linear(in_features=4096, out_features=4096, bias=False)
)
(post_Attention_layernorm): RMSNorm()
(mlp): MLP(
(dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)
(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False)
)
)
)
(final_layernorm): RMSNorm()
)
(output_layer): Linear(in_features=4096, out_features=65024, bias=False)
)
)
1.3.2 参数量
ChatGLM-6B的参数量如下所示。
总参数量:6,255,206,400
Transformer:6,255,206,400
Transformer.word_embeddings:150,528*4,096=616,562,688
Transformer.layers:201,379,840*28=5,638,635,520
Transformer.layers.0:67,125,248+134,238,208+8192*2=201,379,840
Transformer.layers.0.input_layernorm:4,096*2=8,192
Transformer.layers.0.Attention:50,343,936+16,781,312=67,125,248
Transformer.layers.0.Attention.rotary_emb:0
Transformer.layers.0.Attention.query_key_value:4,096*12,288+12,288=50,343,936
Transformer.layers.0.Attention.dense:4,096*4,096+4,096=16,781,312
Transformer.layers.0.post_Attention_layernorm:4,096*2=8,192
Transformer.layers.0.mlp:67,125,248+67,112,960=134,238,208
Transformer.layers.0.mlp.dense_h_to_4h:4,096*16,384+16,384=67,125,248
Transformer.layers.0.mlp.dense_4h_to_h:16,384*4,096+4,096=67,112,960
Transformer.final_layernorm:4,096*2=8,192
lm_head:4,096*150,528=616,562,688
ChatGLM2-6B的参数量如下所示。
总参数量:6243584000
Transformer:6243584000
Transformer.embedding:266,338,304
Transformer.embedding.word_embeddings:65024*4096=266,338,304
Transformer.rotary_pos_emb:0
Transformer.encoder:5,710,907,392
Transformer.encoder.layers:5710903296
Transformer.encoder.layers.0:203960832
Transformer.encoder.layers.0.input_layernorm:4096
Transformer.encoder.layers.0.self_Attention:35656192
Transformer.encoder.layers.0.self_Attention.query_key_value:18878976
Transformer.encoder.layers.0.self_Attention.core_Attention:0
Transformer.encoder.layers.0.self_Attention.core_Attention.Attention_dropout:0
Transformer.encoder.layers.0.self_Attention.dense:16777216
Transformer.encoder.layers.0.post_Attention_layernorm:4096
Transformer.encoder.layers.0.mlp:168296448
Transformer.encoder.layers.0.mlp.dense_h_to_4h:112197632
Transformer.encoder.layers.0.mlp.dense_4h_to_h:56098816
Transformer.encoder.final_layernorm:4096
Transformer.output_layer:266,338,304
1.3.3 归一化层
由LayerNorm变成RMSNorm。
RMSNorm是对LayerNorm的一个改进,没有做re-center操作(移除了其中的均值项),可以看作LayerNorm在均值为0时的一个特例。论文通过实验证明,re-center操作不重要。
1.3.4 激活函数
由GeLU变成SwiGLU。
2 FlashAttention
这是一个在cuda编程层面提高模型训练速度的技术。
FlashAttention主要是为了做训练提速的,当输入序列较长时,由于self-Attention的时间和内存困惑度会随着输入序列长度的增加成二次方增长,Transformer的计算过程缓慢且耗费内存,所以制约了长度的扩展。因此,如果能够把计算量降下去,长度就自然可以进行扩展。
我们再深入到底层GPU运算。GPU中存储单元主要有HBM和SRAM,其中:HBM容量大但是访问速度慢,SRAM容量小却有着较高的访问速度。例如,A100 GPU有40-80GB的HBM,带宽为1.5-2.0TB/s;每108个流式多核处理器各有192KB的片上SRAM,带宽估计约为19TB/s。
我们再来看看实际做Attention时做的运算,主要包括、、这三个反复执行的操作。就GPU内存利用而言,注意力层面临的主要问题是中间结果P、S和O的大小,需要将它们保存至HBM中,并在注意力运算之间再次读取。因此,FlashAttentio算法,主要解决的是将P、S和O从HBM移动到SRAM,以及反向移动这个瓶颈,并最终减少对HBM的访问。
具体的,其主要思想是将输入的Q、K和V矩阵划分成块(block),将这些块从HBM加载至SRAM中,然后根据这些块来计算注意力输出,这个过程被称为“切片(tiling)”。
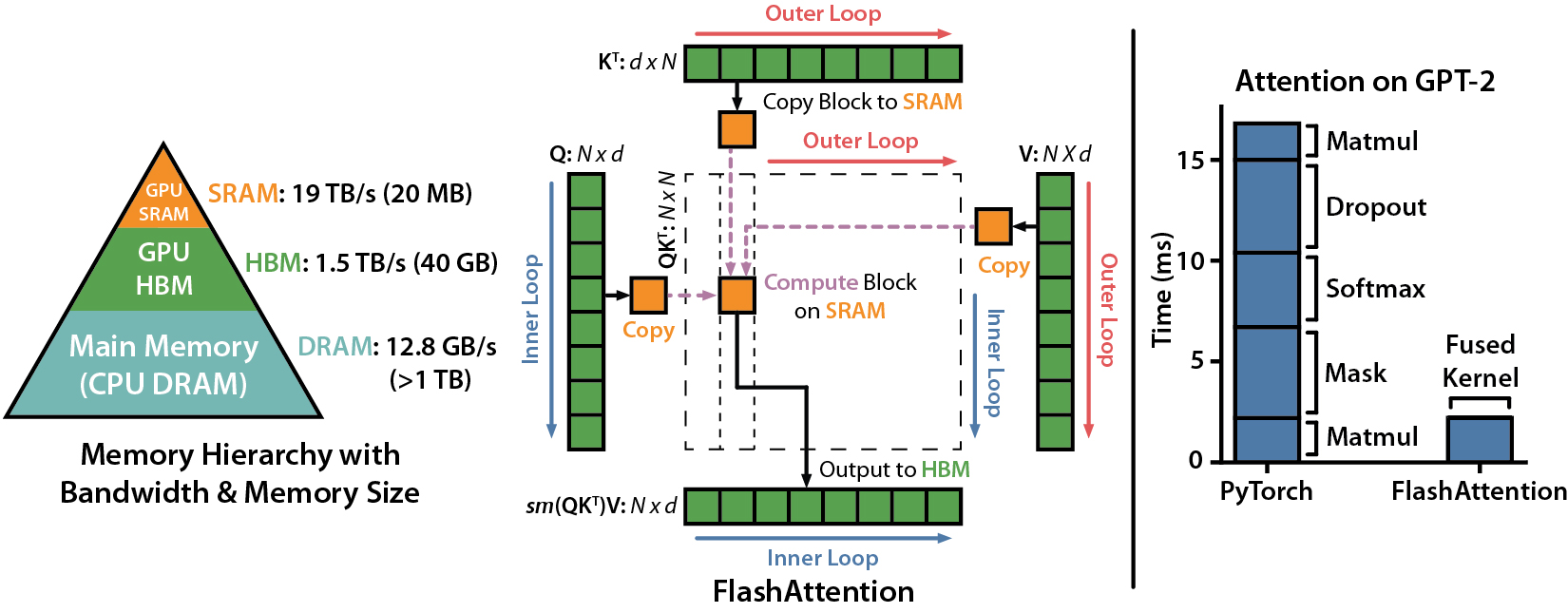
如上图所示,左图中FlashAttention使用切片技术,防止将大型n × n注意力矩阵(虚线框内)存储到HBM中。在外部循环(红色箭头)中,FlashAttention循环遍历K和V矩阵的块,并将它们加载到SRAM中。在每个块中,FlashAttention循环遍历Q矩阵的块(蓝色箭头),将它们加载到SRAM中,并将注意力计算的输出写回至HBM。
3 Multi-Query Attention
该方案目的的是为了保证模型效果的同时加快Decoder生成token的速度。
其实现的逻辑在于:原始的多头注意力(Multi-Head Attention,MHA)在每个注意力头都有单独的线性层用于K和V矩阵,在推理过程中,为了避免重复计算,解码器中之前的词元的键(key)和值(value)被缓存,因此每生成一个词元,GPU内存使用量都会增加。
与此不同,Multi-Query Attention让所有的头之间共享同一份Key和Value矩阵,每个头只单独保留一份Query参数,即只需保留大小为和的两个矩阵,从而大大减少Key和Value矩阵的参数量。
Multi-Query Attention计算中的维度变化如下所示。
隐藏层输入:torch.Size([1, 1, 4096])
经过QKV的线性层:Linear(in_features=4096, out_features=4608, bias=True)
变成QKV:torch.Size([1, 1, 4608])
拆分成Q,K,V:
query: torch.Size([1, 1, 4608])
key: torch.Size([1, 1, 256])
value: torch.Size([1, 1, 256])
Q,K,V分别拆分成多头:
query: torch.Size([1, 1, 32, 128])
key: torch.Size([1, 1, 2, 128])
value: torch.Size([1, 1, 2, 128])
K,V分别复制头:
key: torch.Size([1, 1, 2, 1, 128])
key: torch.Size([1, 1, 2, 16, 128])
key: torch.Size([1, 1, 32, 128])
最终参与多头计算的Q,K,V:
query: torch.Size([1, 1, 32, 128])
key: torch.Size([1, 1, 32, 128])
value: torch.Size([1, 1, 32, 128])
4 测试结果