GPT论文分享:Improving Language Understanding by Generative Pre-Training
大约 2 分钟
GPT论文分享:Improving Language Understanding by Generative Pre-Training
作者证明了通过在大量未标注文本上对语言模型进行生成式预训练,然后在每个特定任务上进行歧视性微调,可以在这些任务上实现巨大收益。与以前的方法相比,他们在微调期间利用面向任务的输入转换来实现有效的转移,同时对模型架构所需的更改最小。
1 模型架构
图1.1展示了本工作中使用的Transformer架构和训练目标和在不同任务上进行微调的输入转换。我们将所有结构化输入转换为Token序列,送入我们的预训练模型+线性层+softmax层进行处理。
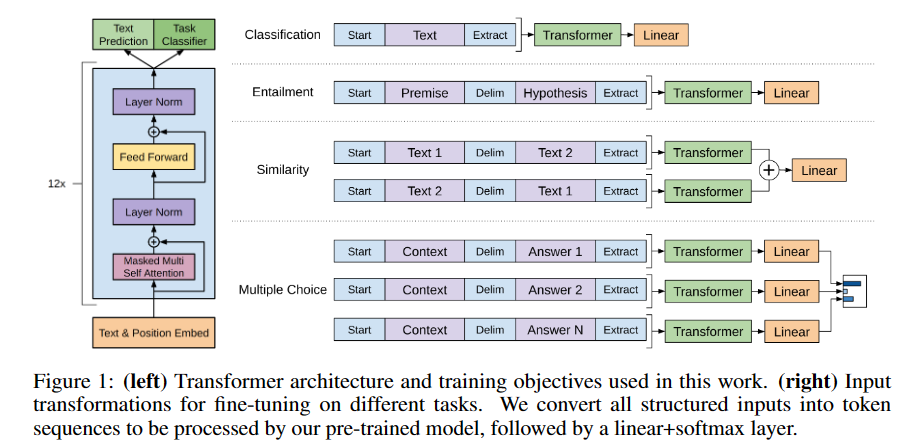
2 训练框架
2.1 无监督预训练
给定一个无监督的token语料库,作者使用标准语言建模目标来最大化以下概率。
其中k是上下文窗口的大小,条件概率P使用具有参数Θ的神经网络来建模。使用随机梯度下降训练这些参数。
在作者的实验中,作者将多层Transformer decoder用于语言模型,这是Transformer的变体。该模型在输入上下文token上应用multi-headed self-attention操作,然后是position-wise前馈层,以在目标token上产生输出分布。
其中是token的上下文向量,n是层数,是token嵌入矩阵,Wp是position嵌入矩阵。
2.2 监督微调
在预训练之后,作者将参数调整为受监督的目标任务。假设有一个标记的数据集C,其中每个实例由一系列输入token以及标签。输入通过作者的预训练模型,以获得最终Transformer块的激活,然后将其送到添加的具有参数的线性输出层来以预测。
因此,优化目标变成了以下式子。
作者还发现,将语言建模作为微调的辅助目标,通过以下方面体现。
(1)改进监督模型的泛化;
(2)加速收敛,有助于学习。
之前的工作也观察到了这种辅助目标的改进性能。具体而言,作者优化了以下目标(带参数λ)。