知识编辑分享
知识编辑分享
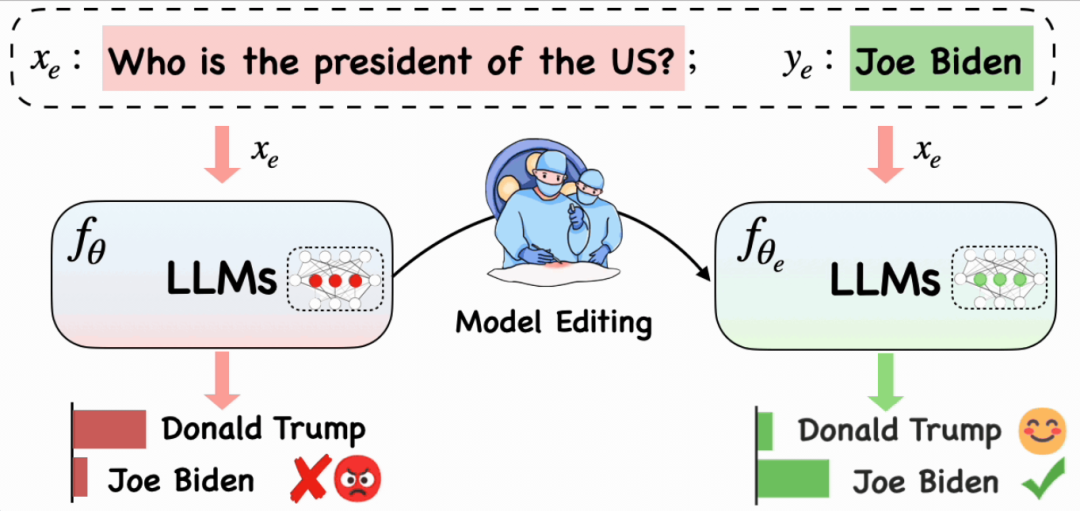
LLMs 受到知识截断和谬误问题的限制情况下,如何高效更新LLMs的参数化知识进而调整特定行为。为解决上述问题,本文介绍EasyEdit知识编辑框架和Memory based、Meta-learning 和 Locate-Then-Edit三种知识编辑方法。
1 背景和目的
LLMs 受到知识截断和谬误问题的限制情况下,如何高效更新LLMs的参数化知识进而调整特定行为。
EasyEdit 框架整合了各种编辑技术,通过统一的框架和接口,EasyEdit 能使用户迅速理解并应用包含在该框架中的主流知识编辑方法,减轻和解决LLMs中存在的谬误。
2 EasyEdit方法和框架
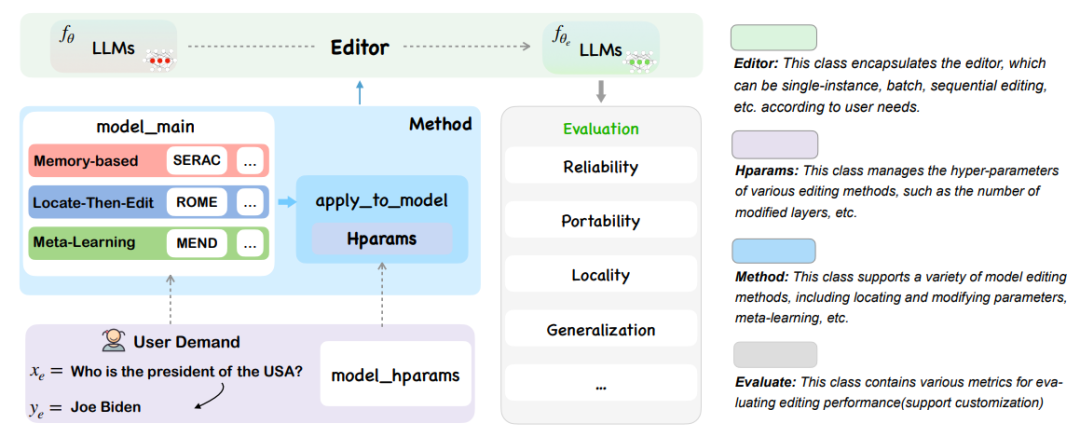
EasyEdit 框架整合了各种编辑技术,支持在不同 LLMs 之间自由组合模块。通过统一的框架和接口,EasyEdit 能使用户迅速理解并应用包含在该框架中的主流知识编辑方法。EasyEdit 具有统一的 Editor、Method 和 Evaluate 框架,分别代表编辑场景、编辑技术和评估方法。
此外,EasyEdit 还提供了五个评估编辑方法性能的关键指标,包括可靠性(Reliability)、泛化性(Generalization)、局部性(Locality)、可移植性(Portability)和效率(Efficiency)
3 EasyEdit实验效果
为验证知识编辑在 LLMs 中的应用潜力,研究团队选用了参数庞大的 LlaMA 2 模型,并利用 ZsRE 数据集(QA 数据集)来测试知识编辑将大量一般事实关联整合进模型的能力。测试结果证明,EasyEdit 在可靠性和泛化性方面超越了传统的微调方法。
4 知识编辑方法
关于 LLMs 的知识编辑研究在各种任务和设置下取得显著进展,包括 Memory based、Meta-learning 和 Locate-Then-Edit 三类方法。
4.1 Memory-Based Editing方法
论文:Memory-Based Model Editing at Scale
基于记忆的大规模模型编辑
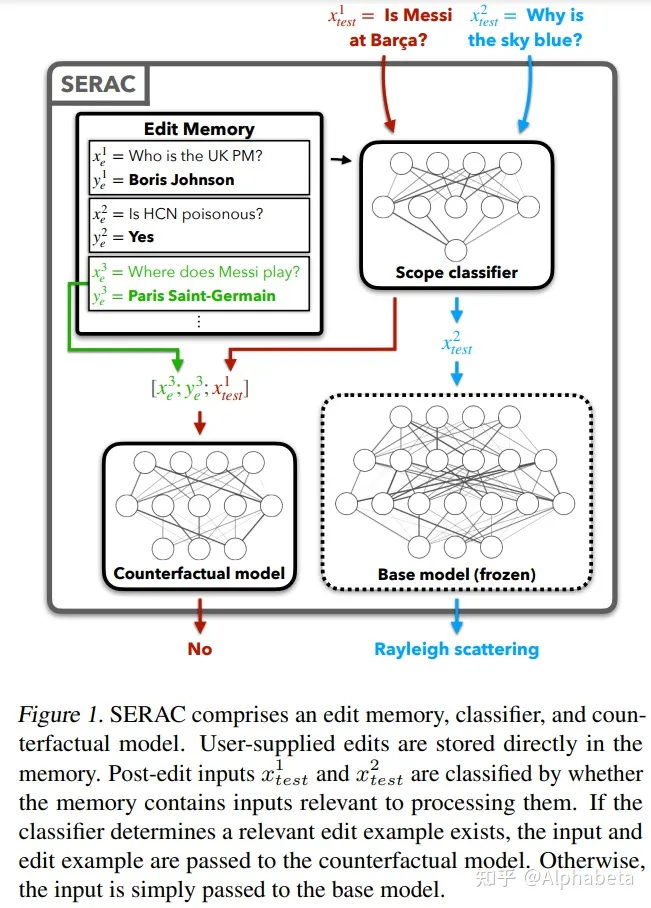
通过添加额外的记忆模块来实现LLM知识的更新
简单来说,一个判别器 scope Classifier,判断是否需要使用原始输出,还是通过counterfactual model,将存储的知识与输入处理得到新的输出。
考虑到不可能完全地契合到需要判断的知识,因此预测一个scope,落在缓存的知识的scope内,就使用 counterfactual model,否则使用 base model。
4.2 Mata-learning-based Editing方法
论文:Editing Factual Knowledge in Language Models
语言模型中的事实知识编辑
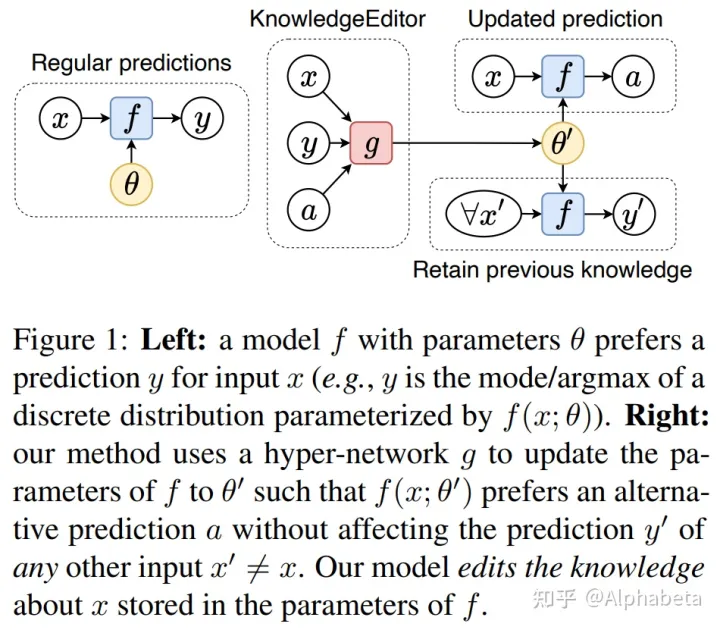
f是原始模型架构,θ是原始模型参数,g是hyper network。接收原始输入、原始输出和目的输出,来预测更新后的模型参数。在实际实现上,g可以是一个LSTM,输出经过不同的MLP网络得到不同的目标系数。
4.3 Locate-Then-Edit方法
论文:Locating and Editing Factual Associations in GPT
GPT 中事实关联的定位与编辑
(1) Locate
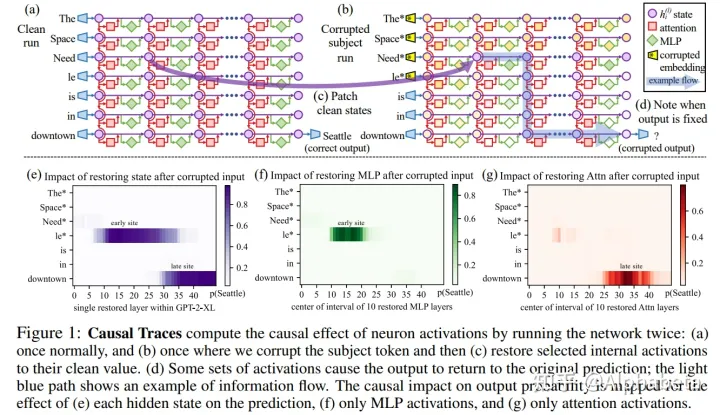
- step1: 首先输入 prompt,比如:“The Space Needle is located in the city of" ,GPT将会输出 Seattle。此时保存下模型内部的hidden state。
- step2: 重新输入上述prompt,在embedding层增加随机噪声。此时模型内部的hidden state应该都有错误了。
- step3: 对step 2中的每个神经元,逐一使用step 1中的hidden state进行恢复(每次只有一个神经元的hidden state是正确的),看模型的输出Seattle的概率变化。
于是,我们就可以使用这种方法,对整个模型内部的神经元对这句prompt的输出的影响大小进行衡量。换句话说,每个神经元对这条知识的影响进行衡量。
(2) Edit
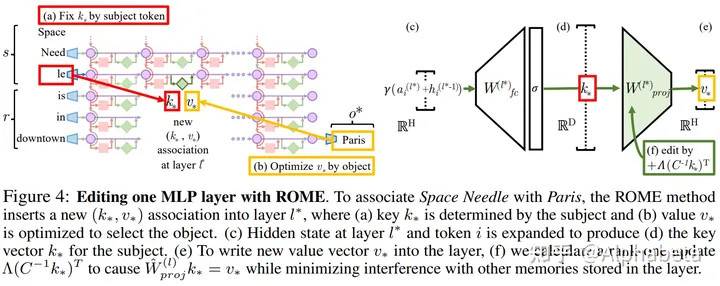
修改的思想为:
- 确定在目标神经元位置上的K 和 V
- K 由多次输入同义的prompt,然后取那个位置的向量的均值得到
- V 由反向传播,根据目标输出得到的梯度,求得目标的 V
根据K和V,求得W,使得 WK = V
评价:这种方法也间接探索了神经网络的可解释性。但步骤相对繁琐。
其中一些也只能凭借经验科学。也不能大量处理知识更新。