LLM如何重映现实世界(一):LLM的信息压缩能力与知识存储方式分享
LLM如何重映现实世界(一):LLM的信息压缩能力与知识存储方式分享
本文主要分享的内容为以下两点。
(1) LLM的信息压缩能力与其智能水平的关系
(2) GPT对知识的提取与存储方式
知乎原文:https://zhuanlan.zhihu.com/p/632795115
版权归属原作者,如涉侵权,请联系删除
一种观点认为:GPT 4 这种 LLM 模型仅仅学会了语言中的单词共现等浅层的表面统计关系,其实并未具备智能,只是类似鹦鹉学舌的语言片段缝合怪而已;另外一种观点则认为:GPT 4 不仅学会了语言元素间的表面统计关系,而且学到了人类语言甚至包括物理世界的内在运行规律,文字是由内在智能产生的,所以 LLM 具备类人智能。
1 预备知识
1.1 什么是NTP任务
目前规模够大的 LLM 模型,在训练基座模型的时候,都采用下一个标记预测(Next Token Prediction,NTP) 任务。Next Token Prediction 如此简单的操作,就是通过语言中前面的单词,来产生下一个单词。
1.2 利用 LLM 进行数据压缩
如果大语言模型具备越强的数据压缩能力,是否意味着它具备越强的 AGI 智能呢?
可以举个例子来解释这种数据压缩能力
把LLM看做函数,根据已有的token,计算下一个token的在词表中的概率分布,根据输出的下一个token的概率分布进行算术编码,使用编码后的数据进行数据传输。
1.3 压缩即智能
如果 GPT 模型智能程度越高,NTP 预测得越准确,则其压缩效率就越高。所以,我们可以根据模型的压缩效率来评估模型的智能程度,模型压缩效率越高,则模型智能程度越高,这是目前 OpenAI 照此思路推进大模型研发方向的一个核心理念。
可以就这个思路深入思考两个相关问题。
(1)第一个问题
上面讲述内容是以数据压缩的视角来看待 LLM 的智能水准,问题是为何模型压缩能力越强,就代表了它具备更高的智能呢?
相对大量数据,数据内在规律的描述,自然就短得多,而模型若能给出越短的描述,说明这个模型学到了更多的内在规律,所以就越聪明。是这个逻辑,举个例子。
假设要传输的序列是连续质数数字序列,下面是gpt-3.5-turbo和oasst两个模型的回答结果。
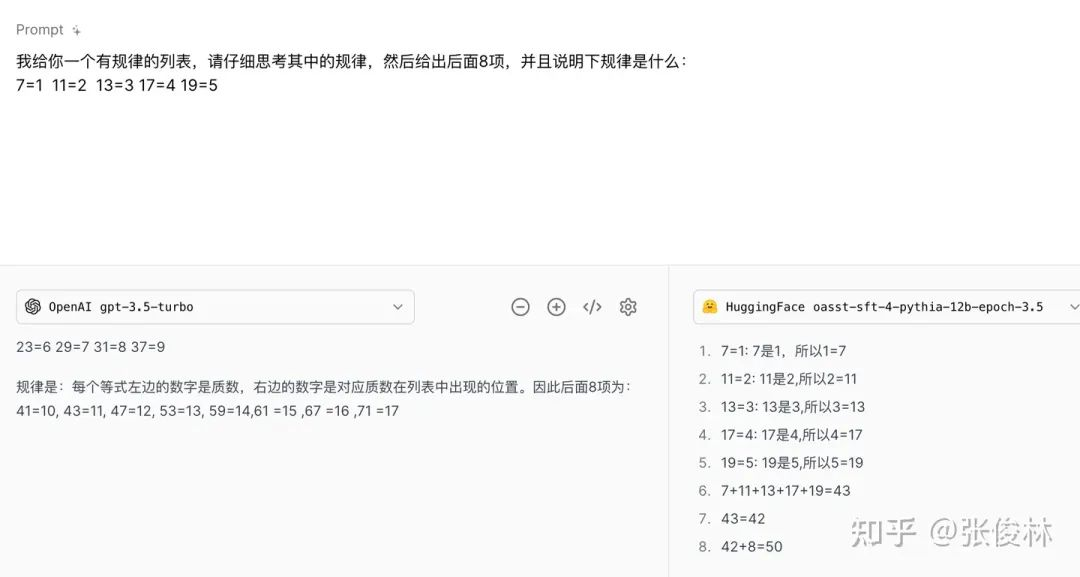
可以看出,gpt3.5 是学会了质数这种抽象概念的,否则这道题很难回答好,如果不理解这个概念,就会出现图右小模型这种不知所云的回答。这一方面说明大模型确实可以学习一些抽象概念,另一方面说明大模型在这方面表现确实比小模型要好。
(2)第二个问题
如果我们更严谨地来看,会发现尽管 LLM 训练过程可以看成是对数据的无损压缩,但是能够达成「无损」 的效果,并不单单靠 LLM,其实是「LLM + 算术编码」一起完成的。
数据无损压缩能力 = LLM 模型的有损数据压缩能力 + 算术编码的编码补偿能力
2 GPT 模型对知识的提取过程
论文:
Dissecting Recall of Factual Associations in Auto-Regressive Language Models
剖析自回归语言模型中事实关联的回忆
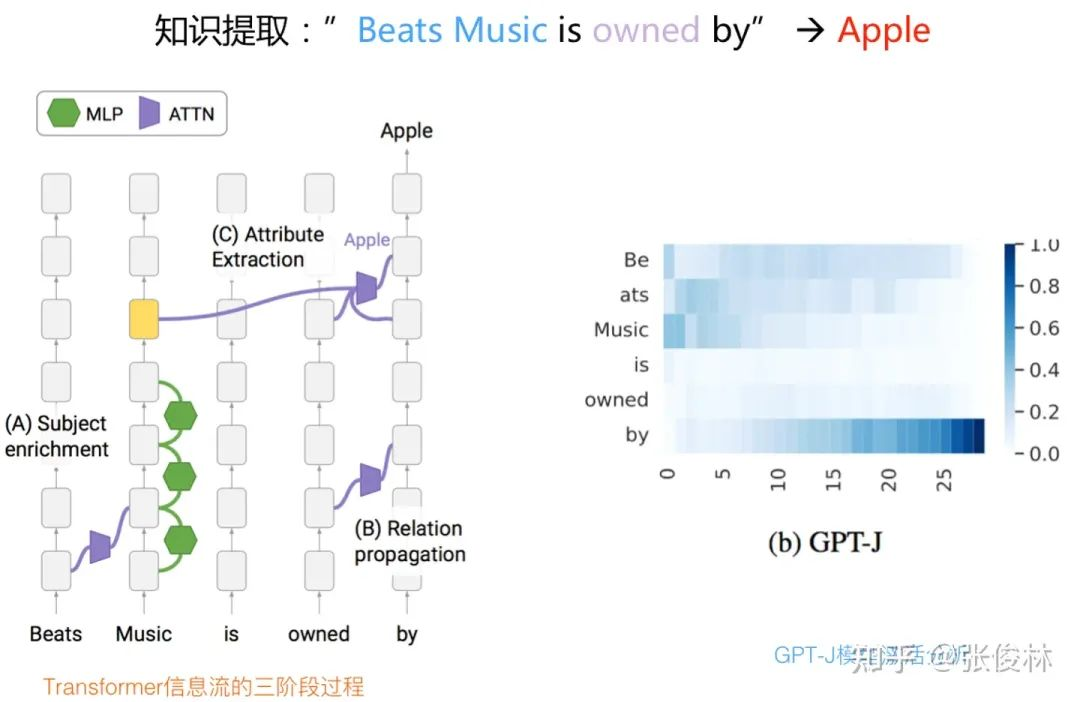
经过研究,发现 GPT 在提取这条知识的时候,经历了明显的三阶段过程,
(1) 主题补充
单词 「music」是描述这个实体最后的、也是最关键的词汇,它的信息在顺着 Transformer block 往上走的过程中,先通过 Attention 把之前的修饰语「beats」 相关信息集成到「music」 对应位置。之后,随着 Transformer 层数越来越高,通过每个 Transformer Block 的 FFN 层,不断往「music」对应的 Embedding 里增加信息,所以随着信息往上层流动,「music」这个单词对应层数的 Embedding,能够触发越来越多的与「Beat music」 相关 「属性」 词汇。这是第一个步骤,整个过程总体发生在 Transformer 的低层。
(2) 关系传播
GPT 模型在 「by」单词这个位置,也就是 NTP 要产生输出 token 的最后一个位置,通过 Attention 把单词「own」 的信息集成到最后位置。这里需要注意一下,最后一个单词对应的 Transformer 位置是比较关键的,因为在它的最上层会给出 Next Token 输出。在推理过程中,GPT 会把输入上文中的重要信息通过 Attention 逐步集成到这个位置上来。这个操作也发生在 Transformer 的低层。
(3) 关系抽取
在「by」 单词位置,也就是最后一个位置的 Transformer 高层,它在低层已经集成了单词「own」 的信息,这个信息在高层,通过 Attention 把「Beat music」 对应的属性「apple」 提取出来。具体提取动作是通过某个 Attention Head 来做到的,而且这篇文章证明了 Attention Head 里会编码 < 实体 - 属性 > 信息,具体例子可以参照下图,这点对应该是个新知识(过去一般认为 Attention 主要是用来进行信息比较和搬运的,它证明了 Attention 也会存储某种知识)。
3 知识点在 Transformer 中的分布
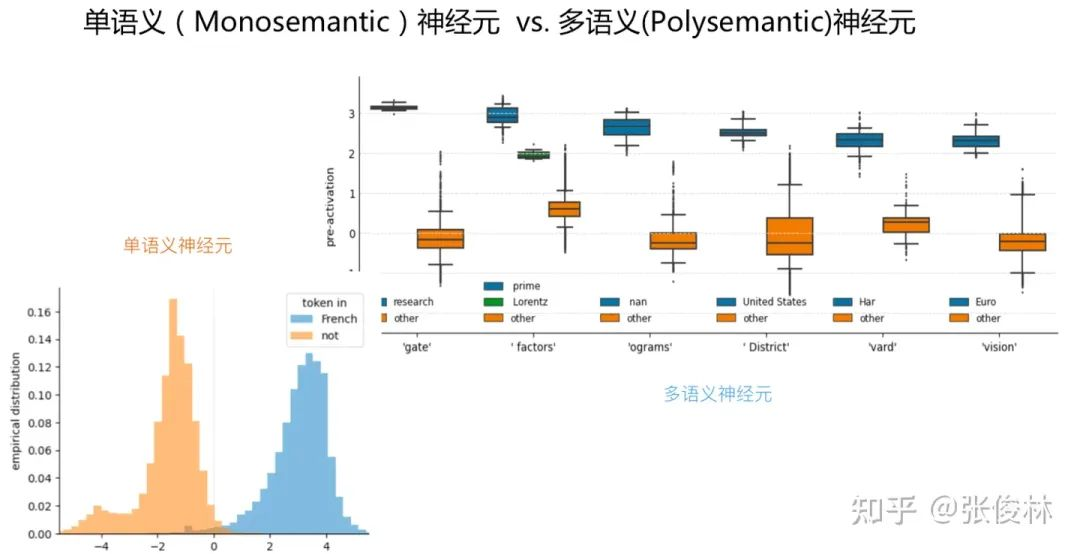
(1)目前发现 LLM 中存在很多单个的神经元,它们各自只对输入里某个特殊的知识点产生响应,也就是说只会被特定输入模式激活,对其它无关输入保持沉默。 一个神经元编码一个知识,完美一一对应,这类 Transformer 中的神经元被称为 「单语义神经元」;很多不同语言含义的知识点都会激活某个神经元,这类神经元被称为「多语义神经元」。
提示
Superposition 概念解释 :一种信息压缩编码机制,假设要编码的特征的数量 n 远远多于网络参数 d,可找到办法,来用 d 维神经元编码比 d 数量大得多的 n 个特征,这种编码机制被称为 superposition,所以它是被发现存在 Transformer 结构里的一种信息压缩编码机制。
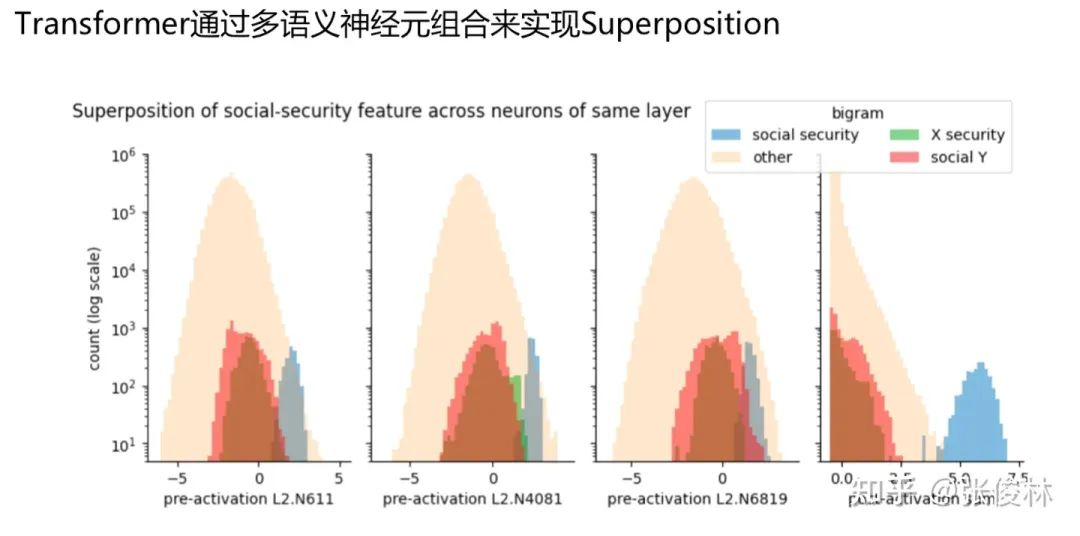
Superposition 和「多语义神经元」 关系密切,目前发现 LLM 内部是这样做的(参考 Finding Neurons in a Haystack: Case Studies with Sparse Probing):如上图所示,LLM 的 Superposition 机制是由多个「多语义神经元」 联合构成的,每个神经元会对输入中的多个不同知识点都有响应,所以仅仅通过一个多语义神经元是无法探测当前是对谁在做出响应,但是如果有多个对某个知识点都有响应的「多语义神经元」,在它们的响应之上做个线性组合,就能探测到输入中我们想识别的那个知识点(上图中蓝色部分)。也就是说,LLM 通过组合多个「多语义神经元」来对某个具体特征或知识点进行编码。所以,多语义神经元和知识点之间的关系是多对多的映射,一个知识点会激发很多对它进行编码的「多语义神经元」,而一个 「多语义神经元」也会对多个输入知识点产生响应。
(2)另外,「Polysemanticity and Capacity in Neural Networks」这个文章指出了,在模型学习过程中,为了增加模型参数的利用效率,单语义神经元会被分配给重要特征;多语义神经元会分配给不太重要的特征。