机器学习之强化学习概述
强化学习(Reinforcement Learning,RL)是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。强化学习是除了监督学习和非监督学习之外的第三种基本的机器学习方法。与监督学习不同的是,强化学习不需要带标签的输入输出对,同时也无需对非最优解的精确地纠正。强化学习被广泛认为是实现通用人工智能(AGI)的关键技术之一。
1 基本概念
所谓强化学习,简单来说是指智能体在复杂、不确定的环境中最大化它能获得的奖励,从而达到自主决策的目的。
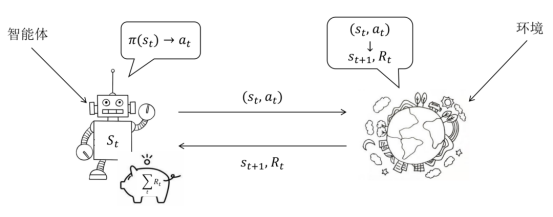
经典的强化学习模型可以总结为图1.1的形式,任何强化学习都包含这几个基本概念:智能体、行为、环境、状态、奖励。根据状态执行动作由模型决定,执行动作后转移到哪个状态由环境决定。
2 马尔科夫决策过程
当且仅当某时刻的状态只取决于上一时刻的状态时,一个随机过程被称为具有马尔可夫性质,即,而具有马尔可夫性质的随机过程便是马尔可夫过程。
为了后续推导的方便,我们引入两个重要的量。为了评估某个状态的整体上的好坏,引入了状态值函数,其定义为状态s未来累积奖励的期望,期望越大说明当前状态越有利。引入状态动作值函数,其定义为状态下采取动作后未来累积奖励的期望。
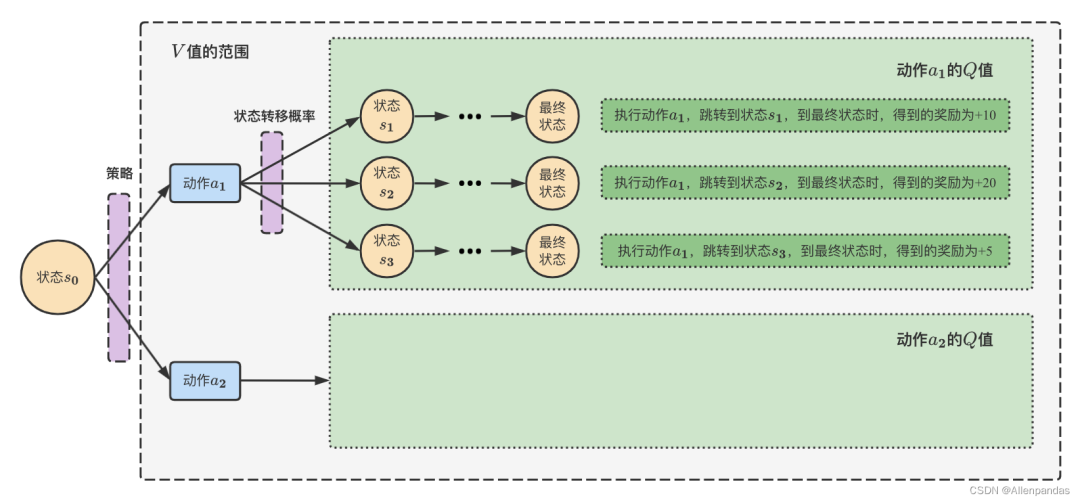
显然模型的优化目标可以用表示。
3 强化学习分类
强化学习算法种类繁多,可按图3.1所示类别粗略分类。
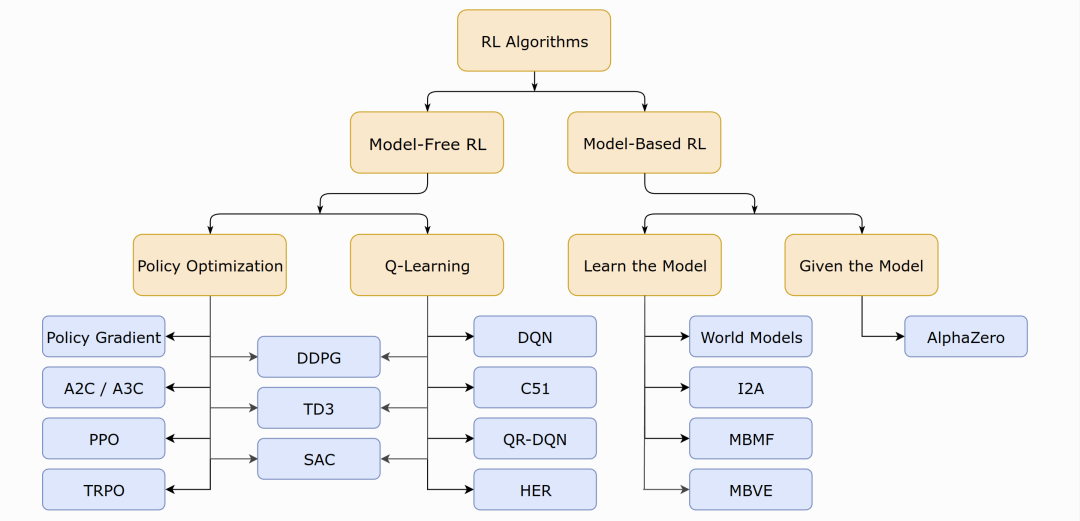
基于模型的强化学习的特点是对环境进行建模,具体而言就是已知和的取值。如果有对环境的建模,那么智能体便能在执行动作前得知状态转移的情况即和奖励,也就不需要实际执行动作收集这些数据;否则便需要进行采样,通过与环境的交互得到下一步的状态和奖励,然后依靠采样得到的数据更新策略。
无模型的强化学习可以分为基于价值的和基于策略的。基于价值的强化学习方法会学习并贪婪的选择Q值最大的动作,能够学习到确定性策略。基于策略的强化学习方法则对策略进行建模,直接对进行优化,一般得到的是随机性策略。
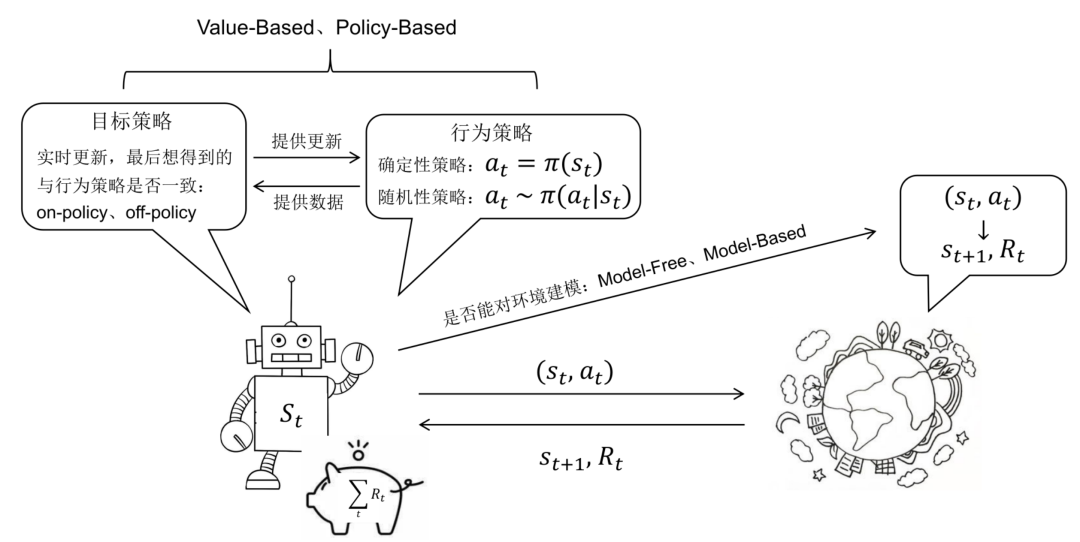
确定性策略是在任意状态s下均选择最优动作,它是将状态空间S映射到动作空间A的函数。它本身没有随机性质,因此通常会结合贪心算法或向动作值中加入高斯噪声的方法来增加策略的随机性。随机性策略是在状态下按照一定概率分布选择动作。它本身带有随机性,获取动作时只需对概率分布进行采样即可。