LLM如何重映现实世界(二):LLM中的知识回路与回路竞争猜想
LLM如何重映现实世界(二):LLM中的知识回路与回路竞争猜想
本文主要介绍LLM中的知识回路以及回路竞争猜想。LLM在完成任务过程中,信息在模型中是如何传递的,以及LLM如何预测下一个token。
知乎原文:https://zhuanlan.zhihu.com/p/632795115
版权归属原作者,如涉侵权,请联系删除
1 LLM中的知识回路
所谓「回路」,指的是某个任务的 Prompt 输入 Transformer 后,信息从底向上传播,直到 last token 最高层 Next Token 输出答案,在网络中存在一些完成这个任务的关键路径,信息主要沿着这条路径向上传播,在传播过程中不断进行信息传递或知识加工, 以此方式来通过 NTP 完成某项任务。
1.1 数学能力的知识回路
提示
论文:How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model
GPT-2 如何计算大于?:在预训练语言模型中解释数学能力
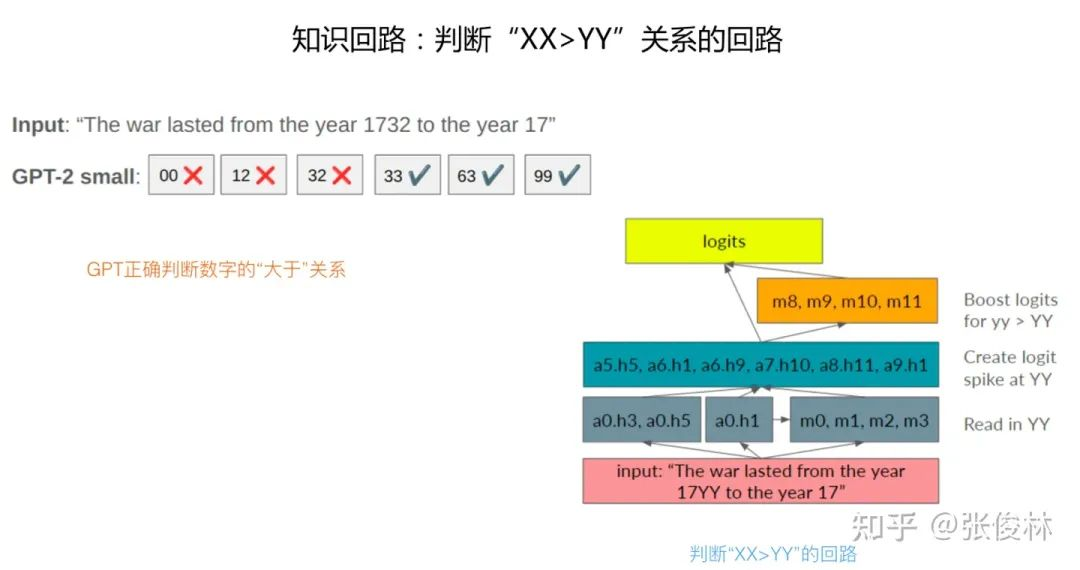
这个工作主要探讨:为何 GPT 模型能够通过预训练获得数学能力。
具体而言,用的是类似The war lasted from the year 17YY to the year 17的 Prompt,GPT 模型可以做到输出的 Next Token 的年份数字 XX 大于 YY,这说明它在预训练中学会了数字间的比较关系。通过探究,发现模型在预训练过程中形成了解决这个问题的知识回路,如图1.1所示。
有两个关键部分,第一个是中间层的某些 Attention Head,比如图中 a5.h5 代表 Transformer 第 5 层的第 5 个 Attention Head,这些 Attention Head 主要作用是聚焦到 YY 年份并向高层传播;另外一个关键是第 8 到 11 层的 MLP 层,这些层的 MLP 完成 「大于」运算,所以最后 GPT 能够正确输出结果。而且,中间层的 Attention Head 和上层 MLP 也有相对应的传递关系,比如第 9 层 MLP 主要接收信息来源于 a9.h1,而第 8 层 MLP 的信息来源则比较多。可以看出,信息从下到上形成了一个特定的传播路径。
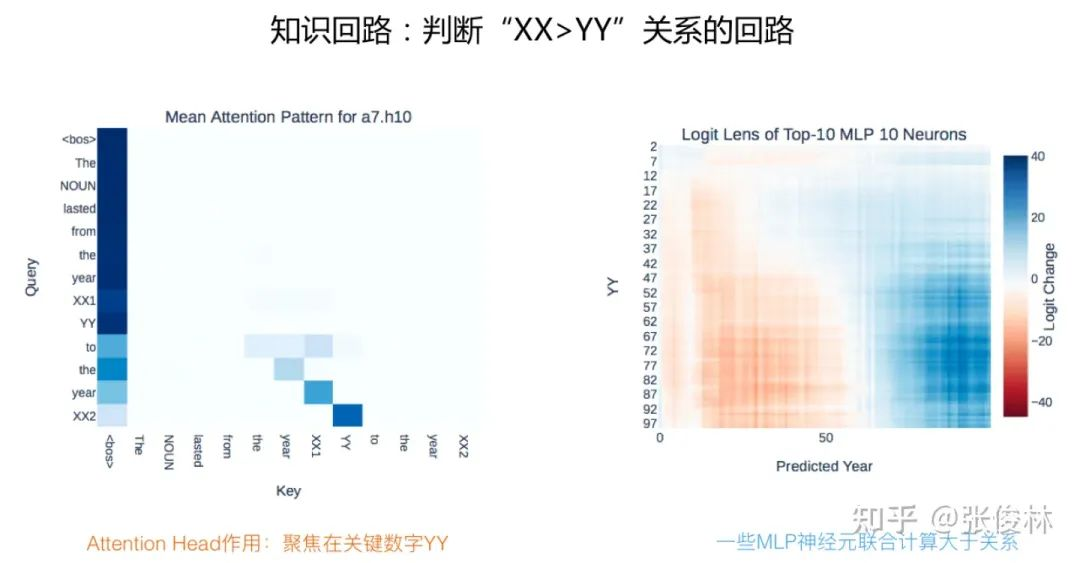
如果再深入探究,会发现是 MLP 中的一些关键神经元完成数学运算的,如图1.2所示,可以探测出第 10 层 MLP 中影响最大的 10 个神经元,这层只用这 10 个神经元就能大致完成 “大于” 运算,而左图则展示了 a7.h10 这个 Attention Head 主要聚焦于关键信息 “YY” 上。另外,该项研究还发现不仅仅上述 Prompt,如果变换 Prompt 形式,但是体现数字比较关系,发现被激活的也是这条回路,这说明这条回路可能专门用于对数字进行关系比较。
1.2 Induction Head回路
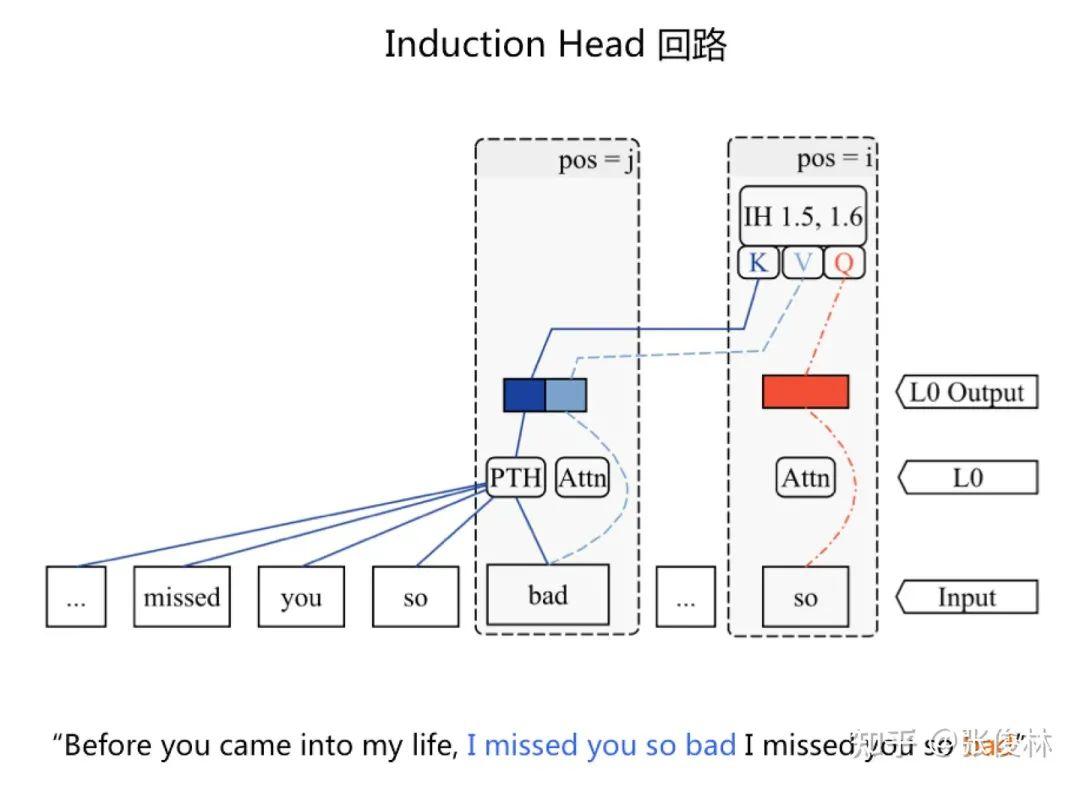
大部分知识回路应由 Attention 和 MLP 共同组成,但是也发现一些以 Attention 为主的知识回路。
典型的例子就是「Induction Head」 回路,多项研究证明这个回路的存在。它的主要作用在于当 GPT 预测 Next Token 的时候,倾向于从上文找到类似的输出模式,并拷贝到后续 Token 输出。
如图1.3所示句子,第二个「so」 是 last token,GPT 此时通过 NTP 将要产生后续 Token,「Induction Head」 回路倾向于从上文中找到相同的 「so」单词,并把上文中跟在「so」后面的单词 「bad」 当作 Next Token 输出。「Localizing Model Behavior with Path Patching」 这项研究探测了 Induction Head 的内在工作机制:当根据第二个单词 「so」 要预测 Next Token 的时候,「so」 本身的内容被拷贝到 Transformer 自己对应 Attention 的 < Query,Key,Value > 中的 Query,而上文内容中出现的 “bad” 单词,通过 PTH (Previous Token Head to key) 这个 Attention Head 将 “bad” 之前内容的语义集成到 “bad” 对应的 Key 里。结果在「so」做 Attention 的时候,两者就得到很高相似性,于是通过 Attention 把「bad」 拷贝到单词 so 的位置,这导致 Next Token 很容易输出 “bad”,就达成了从上文拷贝「so…bad」 的目的。
1.3 Attention 回路
提示
论文:Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
可解释性:GPT-2 small 中的间接对象识别回路
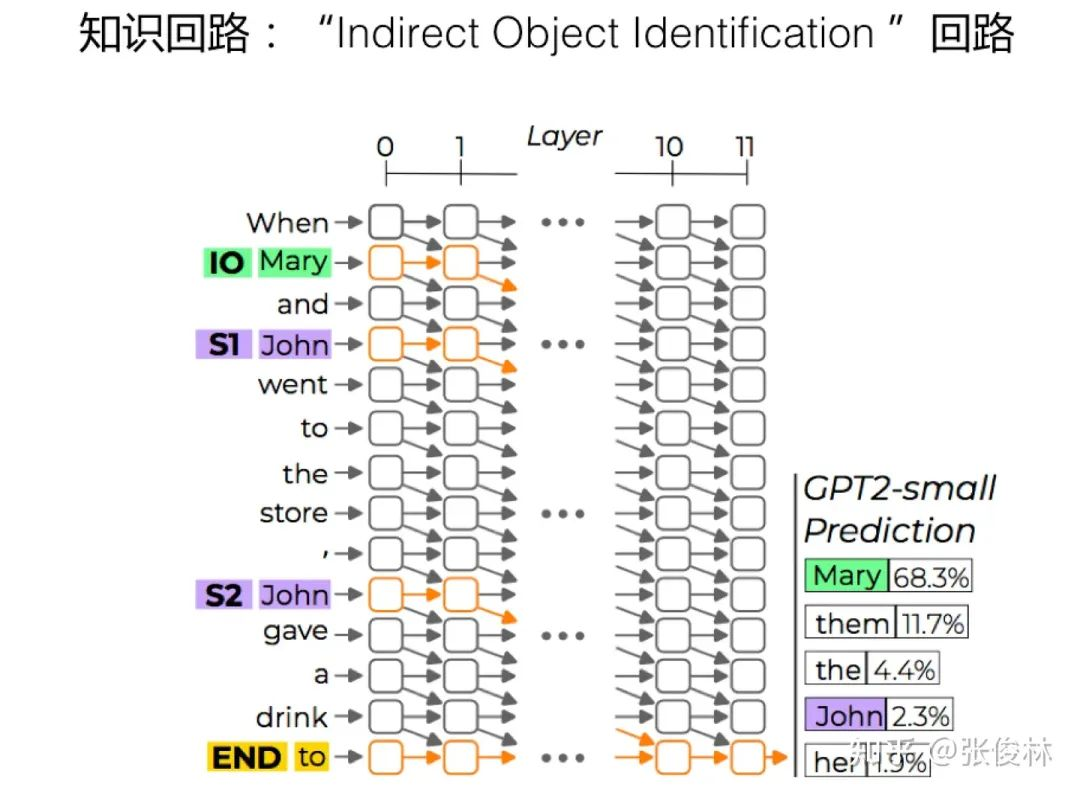
这个工作发现了 Transformer 中存在以 Attention 为主,用于识别 「Indirect Object Identification」的知识回路。所谓「Indirect Object Identification」 ,可以参考图1.4给出的例子,就是说输入有两个实体,一个重复实体,一个非重复实体,如何从中找到正确答案。从上图例子可看出 GPT 是可以输出正确答案 Mary 的,其原因就是模型学会了一个主要由 Attention Head 构成的复杂识别回路
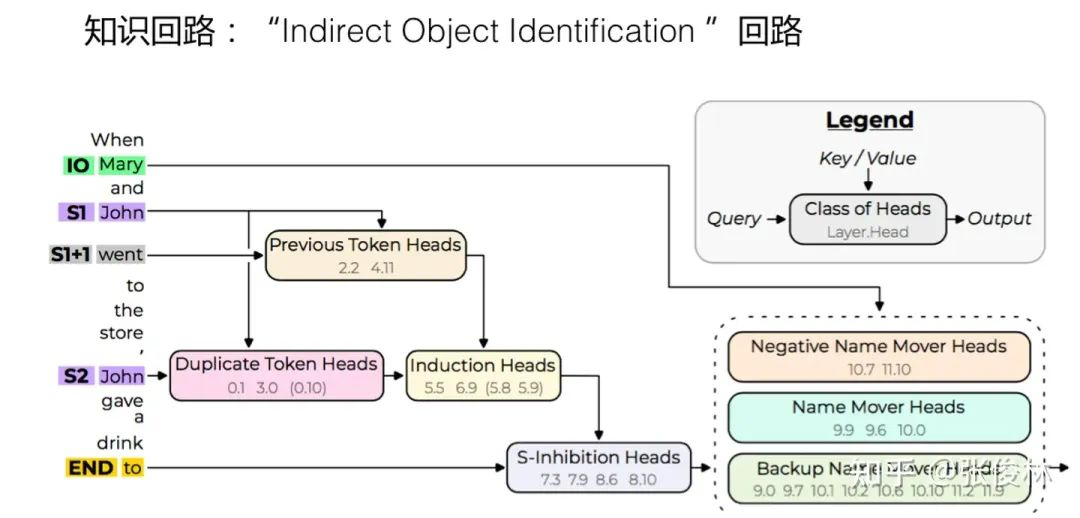
如图1.5所示,「Indirect Object Identification」知识回路识别正确答案,主要由三个步骤构成:
首先,Duplicate Token Heads 用于标识多次出现在句子中的 Token,而 Induction Heads 起到类似的作用;其次,S-Inhibition Heads 在输出 Next Token 的位置发生作用,用于从 Name Mover Heads 的注意力中删除或者抑制重复出现的名字;最后,输出剩余的名称 Token。
由上可看出,LLM 模型在预训练过程中,为了更好地进行 Next Token 预测,学习到了非常复杂的 Attention 知识回路,来执行对某些输入 Token 拷贝并在 Next Token Prediction 结果中输出。
2 回路竞争猜想
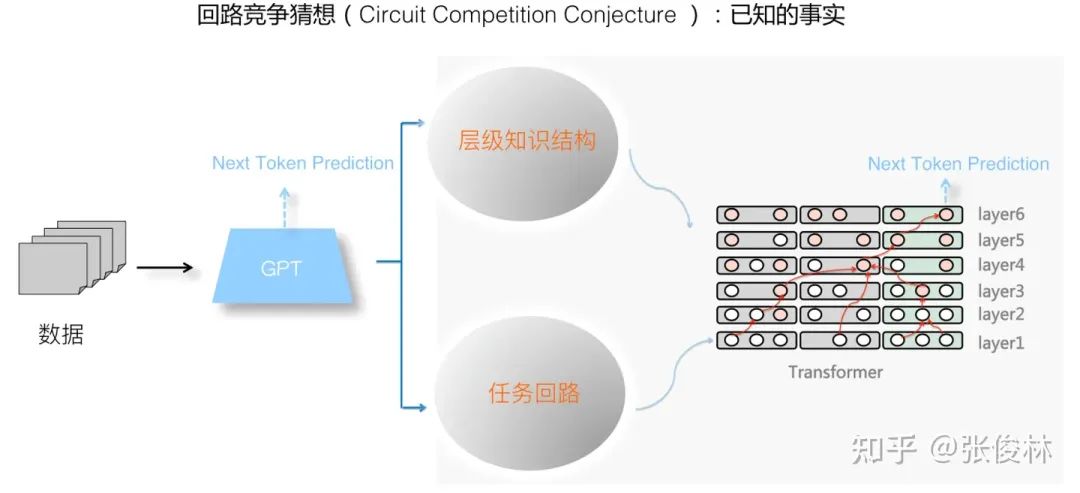
综合上述内容可看出,GPT 模型通过 NTP 任务从数据中学习知识,在模型内部建立起两类知识体系:层级化的知识结构以及各种任务回路,任务回路是在层级知识体系结构上建立起来的,是用于解决某个任务的、由知识点相互激发形成的固定通路。
(1)知识点有不同的抽象层级。
(2)某些知识点之间形成了由底向上的激发关系,激发路径是由下层不那么抽象的知识点逐层激发上层越来越抽象的知识点。
我们在此基础上可以重新看待任务回路的形成。任务回路应该是 GPT 为了更精准预测某种特殊类型数据的 Next Token,从 Transformer 的输入层开始,逐层关联相关的 “激发微结构”,从而形成了一个由低向上逐层激发,并最终关联到输出位置, 以决定输出 Token 概率的完整通路结构(可参考图2.1红线部分勾勒出的某个任务通路)。学会了这种任务回路,如果 GPT 后续再见到此类数据,则 Next Token 预测精准性增加,体现为 NTP 任务 Loss 的降低。比如如果训练数据里大量出现 「13+24=37」这种加减乘除的例子,大概率 GPT 会学会一个用于简单数学计算的任务回路,以此增加等号后数字的 Next Token 预测精准性。
3 参考
[1] Michael Hanna, Ollie Liu, Alexandre Variengien. How does GPT-2 compute greater-than? Interpreting mathematical abilities in a pre-trained language model. arXiv preprint arXiv:2305.00586, 2023
[2] Kevin R. Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in gpt-2 small. In: Proceedings of the 11th International Conference on Learning Representations (ICLR 2023), Kigali, Rwanda, May 1-5, 2023, OpenReview.net, 2023: 1-21