机器学习之强化学习中的价值学习
大约 2 分钟
基于价值的(Value-Based)方法输出的是动作的价值,选择价值最高的动作,也就是通过价值选动作。价值学习经典的算法有Sarsa和Q-learning算法。
1 SARSA

SARSA(State-Action-Reward-State-Action)是一个学习马尔科夫决策过程策略的算法,从名称我们可以看出其学习更新函数依赖的5个值。SARSA是on-policy的强化学习方法,目标策略与行为策略保持一致。
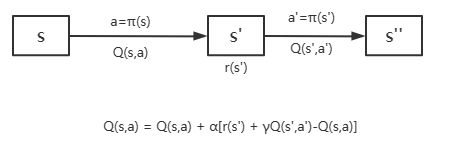
根据状态图可以理解SARSA的更新规则。
2 Q-learning

Q-learning同样根据下一步的状态更新Q值,和SARSA的区别在于直接用下一步的最大Q值作为估计来更新。
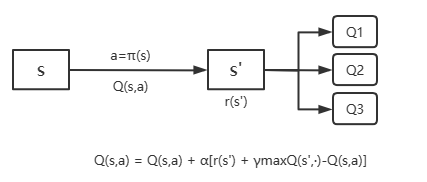
3 on-policy和off-policy
最后来明确下on-policy和off-policy的概念。强化学习包含两个策略,行为策略,智能体遵循该策略选择动作。与之相对的目标策略是我们优化的对象,也是强化学习模型推断时使用的策略。
SARSA的目标策略是优化Q值,根据公式我们知道SARSA是通过预估下一步的收益来更新自身的Q值,而且下一步是按照行为策略选出的,所以它的目标策略与行为策略保持一致,我们称SARSA是on-policy算法。
而Q-learning算法的目标策略是优化下一步的Q表中的最大值,目标策略与行为策略并不一致,我们称Q-learning是off-policy算法。
简单来说,就是看行为策略和目标策略是否相同。