基于Encoder和Decoder的三种架构
基于Encoder和Decoder的三种架构
Transformer由论文《Attention is All You Need》提出,现在是谷歌云TPU推荐的参考模型。论文相关的Tensorflow的代码可以从GitHub获取,其作为Tensor2Tensor包的一部分。哈佛的NLP团队也实现了一个基于PyTorch的版本,并注释该论文。
1 Encoder-Decoder
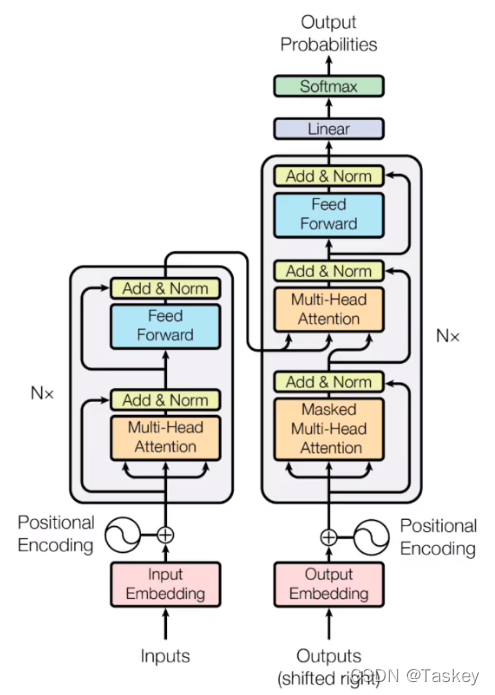
其中Encoder单层包括Self-Attention和MLP,Decoder单层包括Self-Attention,Cross-Attention和MLP。
Cross-Attention的特殊之处在于输入的K和V来自Encoder的输出,而Q来自于自己的Self-Attention的输出。
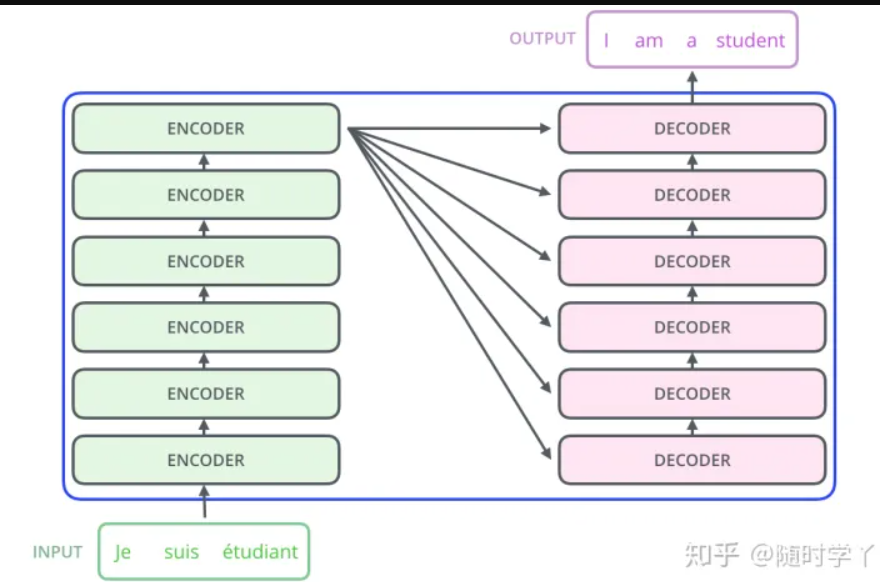
1.1 T5
T5模型的Encoder和Decoder区分的比较明确,在定义时就给出了。
encoder_config = copy.deepcopy(config)
encoder_config.is_decoder = False
encoder_config.use_cache = False
encoder_config.is_encoder_decoder = False
self.encoder = T5Stack(encoder_config, self.shared)
decoder_config = copy.deepcopy(config)
decoder_config.is_decoder = True
decoder_config.is_encoder_decoder = False
decoder_config.num_layers = config.num_decoder_layers
self.decoder = T5Stack(decoder_config, self.shared)
1.2 ChatGLM
ChatGLM之所以是Decoder-Encoder架构,并非是由于结构的原因,而在于它的功能设计,事实上,ChatGLM的所有layer结构一致,并没有Encoder,Decoder之分。
<输入><gmask><bos><输出><eos>
特殊之处在于它的Attention mask,自开始直到gmask是一部分,自bos直到eos是另一部分,被分为两大部分,其中第一部分具有双向特性,左右的token都会影响模型对中间token的预测,符合类Bert模型的MaskLM的特性,因此偏向于Encoder自然语言理解的功能;而第二部分只是单向特性,仅左边token会影响模型对中间token的预测,而右边的不会,符合类GPT模型的AutoRegressiveLM的特性,因此偏向于Decoder自然语言生成的功能。
2 Encoder-only
多个只有Self-Attention和mlp的Transformer层串联起来。
3 Decoder-only
Decoder-only架构有两大与Encoder-only架构相区别的特征。
(1)Cross-Attention:具有能接受Encoder输出的Cross-Attention作为中间层。
(2)past_key_values:在进行生成任务时,可以直接在Decoder的每一个layer内的Self-Attention添加上一步key和value,进行concate然后计算Self-Attention。
特征(1)发挥作用的时间在于Encoder计算完成后,Decoder计算过程中。特征(2)发挥作用的时间在于生成任务的循环中第2轮及以后Decoder的计算过程中。
3.1 GPT2
既有特征(1)又有特征(2),但是特征(1)的使用需要用户从一开始传入Encoder层的结果,也就是只有接受Encoder输出的Cross-Attention,但自己没有产生Encoder输出的能力。当用户不提供Encoder的output时,Cross-Attention模块的计算就会被跳过。
3.2 Bloom
只有特征(2)。
3.3 Llama
只有特征(2)。
4 总结
其实对Decoder-only和Encoder-only这两种,在Transformer的结构上已经近乎没有什么区别,Decoder最标志性的Cross-Attention往往不发挥作用甚至不存在。相比结构,更重要的是功能上的区别,即语义理解是双向性的还是单向性的,所做的任务是NLU还是NLG,Attention mask是对称阵还是上三角矩阵,这里才是决定一个模型所采用的架构的关键所在。