ChatGPT相关技术介绍
首先回顾了GPT系列模型的发展历程,然后介绍了ChatGPT模型最重要的技术指令微调,最后介绍了上下文学习。
1 GPT系列模型发展历程
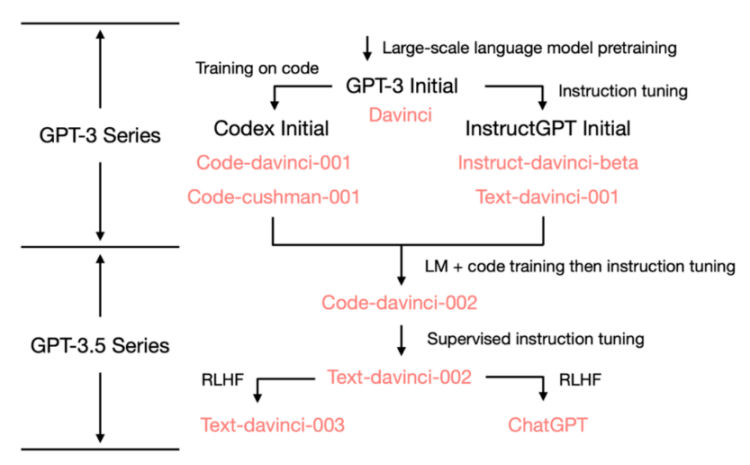
2020年7月,OpenAI发布了模型索引为的davinci的初代GPT-3论文,从此它就开始不断进化。总体分为两大类,第一类是在代码上训练,称其为Codex系列;第二类是使用指令微调的InstructGPT系列。
2022年5-6月发布的text-davinci-002是一个基于code-davinci-002的有监督指令微调(Supervised Instruction Tuning)模型。然后是text-davinci-003和 ChatGPT,它们都在2022年11月发布,是使用的基于人类反馈的强化学习的版本指令微调(Instruction Tuning with Reinforcement Learning from Human Feedback)模型的两种不同变体。
2 指令微调
指令微调(Instruction Tuning)的提出来自于Google的一篇论文[1],结合了微调和提示两个范式的优点,即用prompt格式的训练数据进行finetune,以使模型具备人类倾向的回答问题能力。
在 2022 年 3 月,OpenAI 发布了指令微调[2]的论文,其监督微调(Supervised Instruction Tuning,SFT)的部分对应了davinci-instruct-beta和text-davinci-001。
We focus on fine-tuning approaches to aligning language models. Specifically, we use reinforcement learning from human feedback (RLHF) to fine-tune GPT-3 to follow a broad class of written instructions.
3 模型的训练方法和数据集
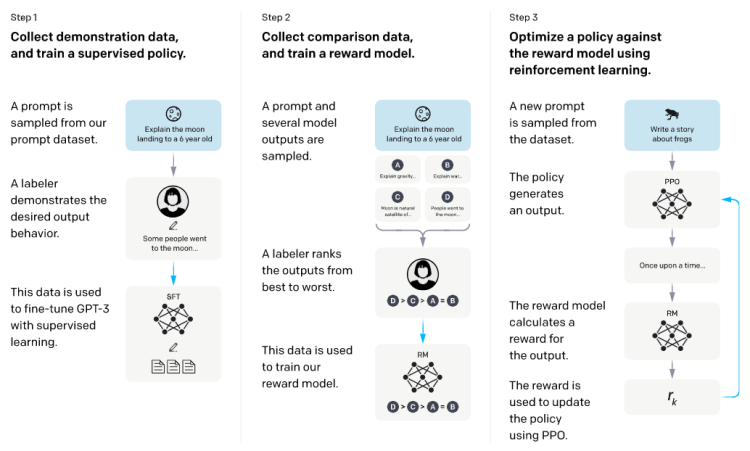
(1)SFT阶段,使用人工标注prompt数据集的答案用来finetune模型。这一步得到的模型是davinci-instruct-beta。
(2)奖励模型阶段,通过对模型输出答案打分来训练奖励模型(Reward Model,RM)。RM就是基于第一步生成的SFT6B版本,去除最后一次反嵌入层,起到了扩充LLM模型高质量训练数据的作用。
推理打分:选择了一部分prompt,由SFT模型随机生成多个答案(4-9个),人工对这些答案从到坏进行排序。这构成了一个新的监督训练数据集,排序是这些数据的label。新的数据集被用来训练RM。--ChatGPT是如何工作的
(3)PPO阶段,使用RM来更新ppo策略,从而使GPT产生的答案更偏向于标注人员的喜好。
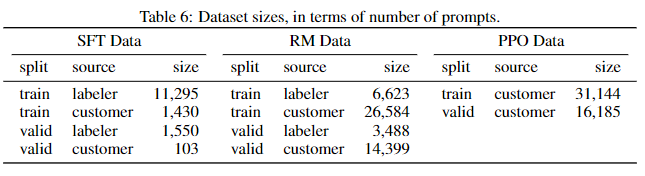
据推测,ChatGPT使用了和text-davinci-003相同的训练方法,采用了不同的数据集,而且更加注重生成答案的无害性和对话性。
合理分析:OpenAI官网的ChatGPT的训练流程和InstructGPT基本一致,除了ChatGPT是基于GPT3.5系列的,再根据InstructGPT发布后半年多才发布ChatGPT,推测是因为初始PPO策略训练的模型太过随心所欲,不能满足无害性等要求,而在调试的过程中GPT3.5系列已经训练完成,所以直接基于GPT3.5系列进行训练。
4 上下文学习
上下文学习(In-context Learning,ICL)[3]是从类比中学习,和人类的决策相似。
ICL只存在一次前向传播中,还是会被模型记住?论文中ICL的测试数据,类似于下图所示,每次预测都需要结合之前的几个demonstration,由此推测ICL并不会被模型记住。结合对text-davinci-003的测试,在一次调用中教会它数学题,之后单独询问,模型并不能正确回答,由此可以证明ICL只存在于一次前向传播。
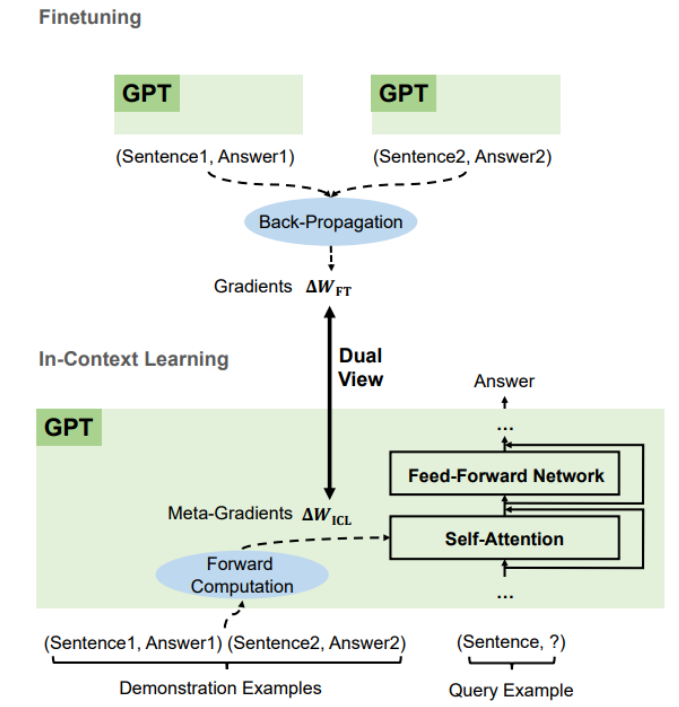
ICL是一个元优化的过程,可以看做隐性微调。GPT首先根据演示示例生成元梯度,然后将这些元梯度应用于原始GPT以构建ICL模型。
Considering that ICL directly takes effect on only the attention keys and values.
ICL只对attention有影响。
5 参考
[1] Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, et al. Finetuned language models are zero-shot learners. In: Proceedings of the 10th International Conference on Learning Representations (ICLR 2022), Online, April 25-29, 2022, OpenReview.net, 2022: 1-46
[2] Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, et al. Training language models to follow instructions with human feedback. In: Advances in Neural Information Processing Systems 35 (NeurIPS 2022), New Orleans, Louisiana, USA, November 28-December 9, 2022, MIT Press, 2022: 27730-27744
[3] Damai Dai, Yutao Sun, Li Dong, Yaru Hao, Shuming Ma, Zhifang Sui, et al. Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers. arXiv, 2023